- HOME
- S4コーディング入門(第3回)具体的なモデルでテクニックを紹介

更新日:2025年2月12日 17:22
公開日:2024年7月16日 11:07
はじめに
本連載の第1回と第2回では、S4本体の機能を中心にコーディング上のノウハウをお伝えして参りました。今回からは「S4プロジェクトを思い通りにカスタマイズする」ために、具体的なプロジェクトを通じてテクニックを見ていきます。基本的には「ミニマル」サンプル、すなわち「離散-ミニマル」および「エージェント-ミニマル」以下のサンプルプロジェクトについて解説します。
今回扱うプロジェクトは以下になります。
- ナンバリング:フロー上を流れるアイテムに対する識別番号を作成する方法を示します。ナンバリングのアイデアは後に扱う様々なプロジェクトでも頻出するため、最初にご紹介いたします。
- グローバルなモニター: プロジェクト作成ではシミュレーション中の出来事をモニターで把握するのが一般的です。本プロジェクトではpsim言語上の Monitor クラスを用いて、アイコンとしてのモニターでは難しい横断的な監視を行う方法をご紹介いたします。
ナンバリング
フローアイテムは Python オブジェクトであるため、フローアイテム同士をメモリアドレス( id() )で区別することは可能です。しかしながら、 id() は桁の多い数値でありアイテム自体の認識方法としてはわかりづらいため、アイテム自身にID属性を持たせることがよく行われます。ここではプロジェクト「ナンバリング」でアイテムごとに異なるIDを割り振る方法を解説いたします。
まずプロジェクトを開きます。S4のメニュー「プロジェクト」→「プロジェクトのインポート」でファイルダイアログを開き、(S4のインストールフォルダ (通常は C:\Program Files\Mathematical Systems Inc\S-Quattro Simulation System V6))\samples\離散-ミニマル\ナンバリング.s4 を選択し、OKします。S4画面左側の「ワークスペース」には開いたプロジェクトが置かれています。「+」をクリックし「モデル」をダブルクリックすることでプロジェクトを開きます。
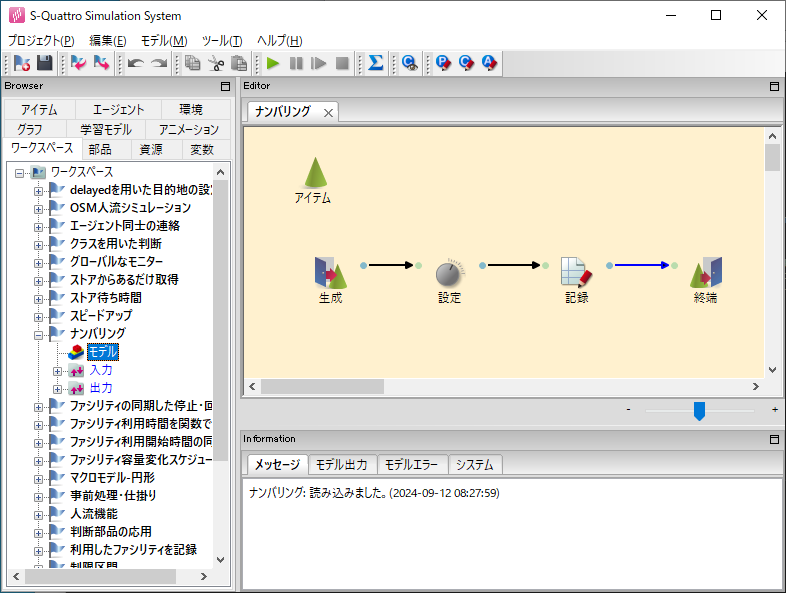
プロジェクト「ナンバリング」のモデル上にある「設定」アイコンの編集画面を開くと、フローアイテムに対して num 属性の付与が行われています。生成方式「固定」では値「 next(numgen) 」に記載した式が毎回評価されるため、アイテムごとにジェネレータ numgen の「次の値」が割り当てられることになります。ジェネレータ numgen の定義はカスタムコードで行っています:
def make_numgen():
num = 0
while True:
num += 1
yield num
numgen = make_numgen()
ジェネレータとしては非常に単純な部類です。内部でカウンタ num を1づつ加算して yield num で「次の値」を返します。 make_numgen 自身はジェネレータではないことが唯一の注意点になります。同関数を呼び出して返ってきた値がジェネレータになります。
対応する生成コードも確認します。まず設定部品 Assign の初期化 __init__ において、「固定」や「 next(numgen) 」が以下のように生成コードとして現れます。
self.itemAttributes = OrderedDict([
('num', (lambda item: next(constantValue(int(next(numgen)))))),
]) # アイテム属性
この設定は run メソッドのローカル関数 assigning (go遷移する状態の一つ)で以下のように反映されます。
for key in self.itemAttributes:
if isinstance(item, FlowItemList):
for it in item:
setattr(it, key, self.itemAttributes[key](it))
else:
setattr(item, key, self.itemAttributes[key](item))
今回、 item は1個ずつ流れてくるため FlowItemList ではなく、 else 節の方が評価されます。 self.itemAttributes[key] で初期化時に設定した lambda 関数を取り出し、それに item を渡して呼び出し、その返り値を組み込み関数 setattr で item の属性として設定しています。
lambda 関数は一見、込み入っていますが next(constantValue( は「固定」の設定に対応し、固定した値を返すジェネレータ、すなわち「引数をそのまま返す」だけです。 int( は「整数」という設定に対応し、引数が整数なら「引数をそのまま返す」だけです。そしてユーザーが記述したコード部分 next(numgen) は評価されるたびに「次の値」を返しますから、全体として lambda の呼び出した結果 next(numgen) を評価した結果と同じになります。
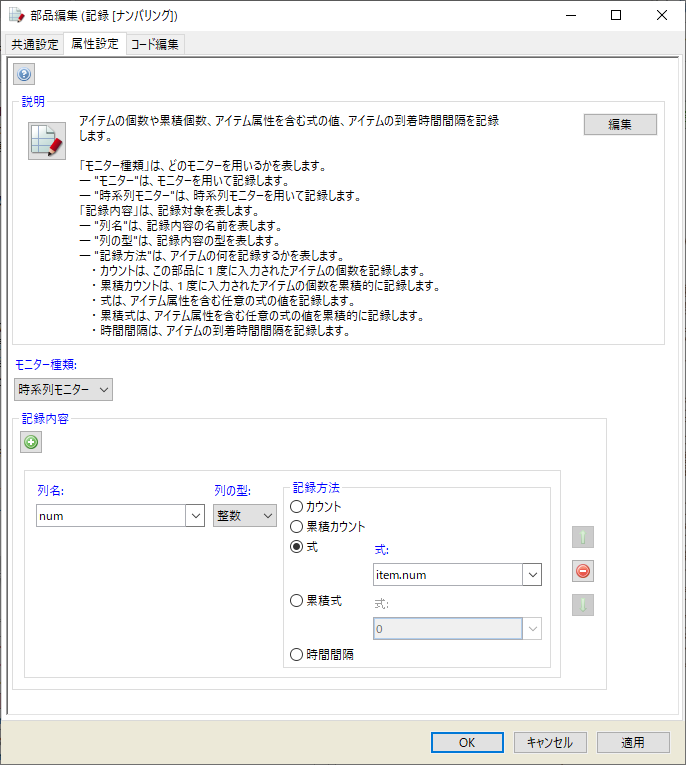
アイテム識別の設定については一通り説明しました。次に識別用のアイテム属性 num の利用について見て参ります。設定部品の次にある記録部品を開くと、以下のようになっています。 num は item.num で参照されています。
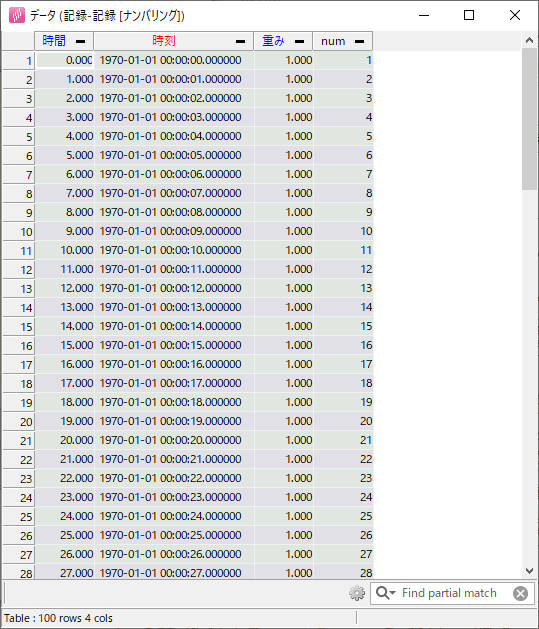
結果も見ておきます。ワークスペースから「ナンバリング」を開き「出力」→「default」→「記録-記録」で右クリックし、「データを表示する」で記録部品の結果を開くと、以下のようになっています。各アイテムがユニークな番号 num を持っていることが確認できます。
以上で「ナンバリング」の説明を終えます。アイテム同士を識別する機会は非常に多いため、今後も繰り返し利用します。また記録部品を用いたシミュレーションの動作確認も頻繁に利用します。
グローバルなモニター
記録部品は流れてきたアイテムの属性を観察する際に威力を発揮します。一方、テーブル形式で記録を行いたい対象はそれ以外にもあり、そのような場合は記録部品が内部的に利用している Monitor や TimeMonitor を直に呼び出すことで一般的な記録を行うことが可能です。ここではプロジェクト「グローバルなモニター」で複数の部品の挙動を横断的に観察するテクニックをご紹介いたします。
まずプロジェクトを開きます。S4のメニュー「プロジェクト」→「プロジェクトのインポート」でファイルダイアログを開き、(S4のインストールフォルダ (通常は C:\Program Files\Mathematical Systems Inc\S-Quattro Simulation System V6))\samples\離散-ミニマル\グローバルなモニター.s4 を選択し、OKします。S4画面左側の「ワークスペース」には開いたプロジェクトが置かれています。「+」をクリックし「モデル」をダブルクリックすることでプロジェクトを開きます。
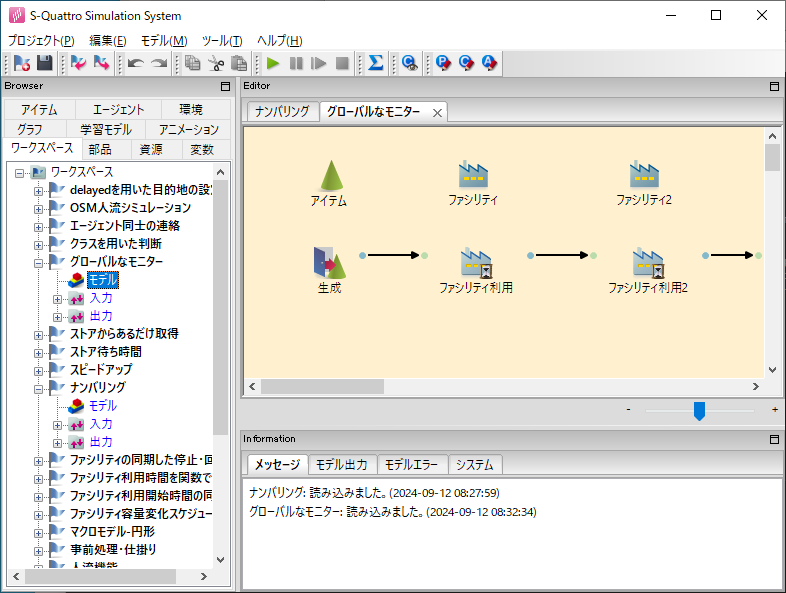
まずカスタムコードを開くと、冒頭にて本プロジェクトの概要説明が記載されています。その下には関数 _sim_before の定義があります。
def _sim_before(sim):
# モニターの登録
sim.addMonitor(usetime_monitor)
sim.addMonitor(facility_monitor)
_sim_before は単なる関数ではなく、シミュレーション開始前に一度だけ呼ばれる関数になります。カスタムコード自体がそのような性質を持ちますが、 _sim_before はシミュレーターのインスタンス sim を引数としており、 sim が持つ addMonitor メソッドでモニターの登録を行うのがここで _sim_before を利用する理由になります。
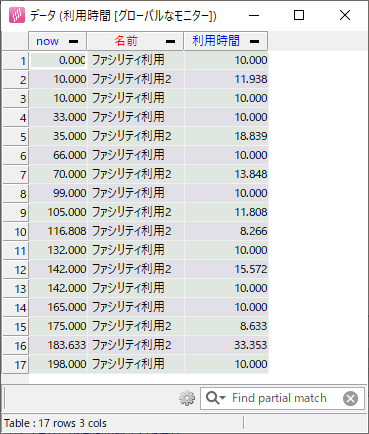
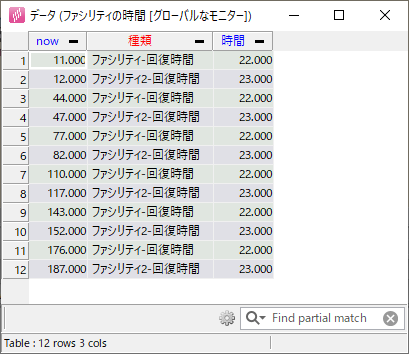
モニターそのものはカスタムコードで定義されています。これはプログラム的にはグローバル変数、すなわち「グローバルなモニター」であり、生成コード上の任意の箇所から参照できます。 name で指定した「ファシリティの時間」「利用時間」がそれぞれ出力の名前として現れます。
usetime_monitor = Monitor(["now", "名前", "利用時間"], ["f", "o", "f"], name = "利用時間") facility_monitor = Monitor(["now", "種類", "時間"], ["f", "o", "f"], name = "ファシリティの時間")
次にモデルの観察に移ります。本プロジェクトにおいて、モニターへの記録はコード編集画面上で行っています。
まず「ファシリティ利用」と「ファシリティ利用2」の「コード編集」タブを開きます。いくつか存在するローカル関数のうち using の中で、カスタムコードで定義したグローバルなモニター「利用時間」を参照し、記録(observe)を行っています。
次に「ファシリティ」と「ファシリティ2」の「コード編集」タブを開きます。こちらは部品と違い初期化時の設定という形で中央のペインにて update_grepair_with_observe を呼び出しています。これはカスタムコードで定義した関数です。意味は次の通りです:「属性設定」タブの「停止確率」で「停止間隔」と「回復時間」の設定を行っています。これは「コード編集」タブの一番上のペインで辞書 keys のキーとしてコード生成されます。
keys.update(gfailure = constantValue(11.0), grepair = constantValue(22.0))
gfailure が「停止間隔」、 grepair が「回復時間」です。カスタムコードの update_grepair_with_observe では、引数 keys でこの辞書を参照し、キー grepair に対する値を
keys.update(grepair = grepair_with_observe(grepair, kind))
で更新しています。 grepair_with_observe もカスタムコードで定義してあって、引数であるジェネレータ grepair を「ファシリティの時間」モニターへの記録(observe)でラップするような内容になっています。
まとめると「利用時間」でファシリティ利用2個の記録を、「ファシリティの時間」でファシリティ2個の記録をそれぞれ行っています。実際に結果を見ると、どちらから出された記録なのかも含め、同じ種類の要素の記録が1つの出力上でまとめて出力されていることがわかります。
おわりに
第3回となる今回は2種類のサンプルプロジェクト「ナンバリング」「グローバルなモニター」についてご紹介しました。ミニマルと付いている「離散-ミニマル」に属するサンプルプロジェクトは単一の課題に注目して組み立てたプロジェクトであり、「S4プロジェクトを思い通りにカスタマイズする」ための直接的なアイデアを与える可能性が高いものになっています。今後の記事でも「離散-ミニマル」のプロジェクトを見て参ります。









