- HOME
- 強化学習とは?機械学習との違いや製造業における具体例

更新日:2026年6月10日 16:14
公開日:2021年10月26日 12:15
かつては囲碁や将棋で AI が人間を超えるのにはもうしばらくの年月が必要と言われていました。しかし AI は従来の予想を覆すほど急速に進歩し、今や AI が人間よりも強いのは当たり前で、プロ棋士が AI を使って勉強する時代になりました。囲碁や将棋の AI が急速に強くなるきっかけとなったのが、強化学習と呼ばれる技術です。
囲碁や将棋の他にも、自動車の自動運転、システムの自動制御などの分野で強化学習が活用されています。最近は製造業の生産工程での強化学習の活用のご相談が増えてきました。今回は、強化学習と機械学習の違いといった基礎知識から、製造業を中心とした実務での活用方法、幅広い業界での具体的なユースケースについて、NTTデータ数理システムの有識者である松下さんにインタビューしました。。

NTTデータ数理システム シミュレーション&マイニング部に所属。機械学習・AI・強化学習・シミュレーションに関する技術課題に対して、論文調査からモデル開発やプログラミングまでを一貫して担当。お客様の課題に対して、手法を実装し考察を繰り返す、実験系(試行錯誤をしながら課題を追及すること)のお仕事を中心に活動。
強化学習とは
強化学習の概要、教師あり学習との違いを教えてください。
松下 強化学習は機械学習の分野の1つです。機械学習の中にはいくつかのタスクの枠組みがありますが、多くの人が典型的にイメージするのは教師あり学習ではないでしょうか。教師あり学習ではあらかじめ答え(正解ラベル)が付与された問題(特徴量)を大量に学習させて、新たな問題が入力されたときに答えを出力できる AI を作成することを目指します。強化学習も何らかの正解に向けて判断をする AI を作るという意味では似ているのですが、正解に対する考え方に特徴があります。強化学習では、AI(エージェント)に何らかの選択をさせたときにその行動に対する評価(報酬)を与えて、評価が大きくなるような行動の仕方を学習させていきます。教師あり学習の正解ラベルと異なり、報酬はある1つの行動に対して即座に与えられる必要はなく、状況に応じて何度かの行動を行った結果に対して与えられる形でかまいません。
例えば将棋の次の一手を考える場合、教師あり学習的な発想で盤面状況(特徴量)に対して最適な一手(正解ラベル)を人間が付与して学習させるというのは非常に困難です。素人には一見悪手に見える手が、勝利につながる最善手であるというのは珍しいことではありません。トッププロ同士の対局では解説のプロ棋士でもその一手が良い手なのかどうかの判断に悩むこともあります。一方で、局面が進んだある盤面に詰みが成立しているかどうかは、ルールさえわかっていれば簡単に判断して情報として与えることが可能です。この場合、強化学習で最終盤面での勝敗を報酬として設定することで、短期的な形勢判断に囚われず最終的な勝利に向けて打ち手を選ぶという学習を行うことができます。
現時点で手に入っている情報だけで判断ができるという場合は教師あり学習を適用する場合が多いと思いますが、時間経過とともに変化する環境に応じて適切な判断を繰り返さないと良い結果が得られないというような問題設定は強化学習の使いどころです。囲碁や将棋のようなターン制のゲームや、この後ご紹介する生産工程の自動化はまさに強化学習向きの課題です。
製造業の生産工程の強化学習の適用事例を通して
製造系で強化学習を活用するご相談は増えていますか?
松下 インダストリー4.0 や FA(Factory Automation)の流れで生産工程を自動化したいというご相談は多く、強化学習のご提案をする機会も増えています。今でも将棋や囲碁の例を引き合いに、手法として強化学習を候補にあげながらご相談いただくことも多いです。やはり、プロの棋士達と互角かそれを超える強さを示したのは社会的にも大きなインパクトだったのだなと感じます。
生産工程を例として、具体的な強化学習活用プロジェクトの進め方について
松下 多くの強化学習活用プロジェクトは第一段階でシミュレーターを作るところから始まります。
強化学習は既に観測されたデータを用いて(オフライン)学習を行うこともできるが、データの網羅性が低いと学習の効率は悪い。また、実際にデータを観測しながら(オンライン)学習する場合も、行動に対するレスポンスが悪い場合には試行回数を増やすことができず効率が悪い。さらに、選択肢によっては現実の世界で選択することが難しい場合もあり、そのような場合にも学習の効率は悪くなる。そこで登場するのがシミュレーションである。現実を模したシミュレーターを用いることで、効率的に多くの試行を行い、シミュレーター上の状況を観測する(サンプリングする)ことができ、また、現実世界では選択できない(しない)選択肢をも選択し、実際に失敗をしてみることで、その選択肢を選択しないことを学習することができる。このように、強化学習とシミュレーションは相性が良い。
BUISNESS COMMUNICATION 2019年6月号
雪島レポート:データサイエンスの現場から「機械学習とシミュレーションの融合」より
松下 生産工程の場合は、工場の生産ラインのシミュレーションモデルを実装します。シミュレーションモデルと一口で言ってもいろいろなモデルがあります。シンプルで標準的なのは離散イベントシミュレーションと呼ばれるモデルです。実際の現場の問題を解く際には、離散イベントシミュレーションでは表現しきれない、AGV や作業員の複雑な動きの表現が必要になるこもあり、そのような場合にはエージェントシミュレーションが用いられます。実際にシミュレーションモデルを構築する際には、生産ラインの仕様を伺ってシミュレーションモデルに落とし込んでいきますが、各処理工程や工程間の移動に要する時間などのデータも必要になります。このシミュレーションモデルの構築は比較的ハードルが高い作業で、教師つきデータを用意すればスタートできる教師あり学習との相違点になるかなと思います。
シミュレーターが完成したらそれをブラックボックスな環境として強化学習モデルの学習を開始します。工場の生産工程などの場合は、納期通りに生産が完了することやスループットが向上することをうまい具合に報酬として定量化することによって学習を実現します。
開発に用いるツールなどについて
松下 シミュレーションにおいては当社のシミュレーションソフト S4 Simulation System を用います。S4 Simulation System にはシミュレーターとしての機能や生産ラインをモデリングするためのパーツや API が豊富に用意されているため、スクラッチで実装するのにくらべて効率よく実装できます。(手前みそですが)実装の工数などが大幅削減できて便利だなと思っています。強化学習でアプローチする際は、一般的に生産工程に限らず物理シミュレーションや社会シミュレーションなど、既存のシミュレーターが対応していればそれを使うのがベターですが、ない場合はシミュレーションプログラムをスクラッチで実装することもあります。
強化学習のアルゴリズムはかつては Chainer のライブラリを使用し学習は DQN(ディープラーニングと強化学習を組み合わせた手法)を用いて学習していました。最近ではライブラリが PyTorch に引き継がれているので、PFRL(PyTorchベースの強化学習ライブラリ)を使用します。
開発期間はどの程度かかりますか?
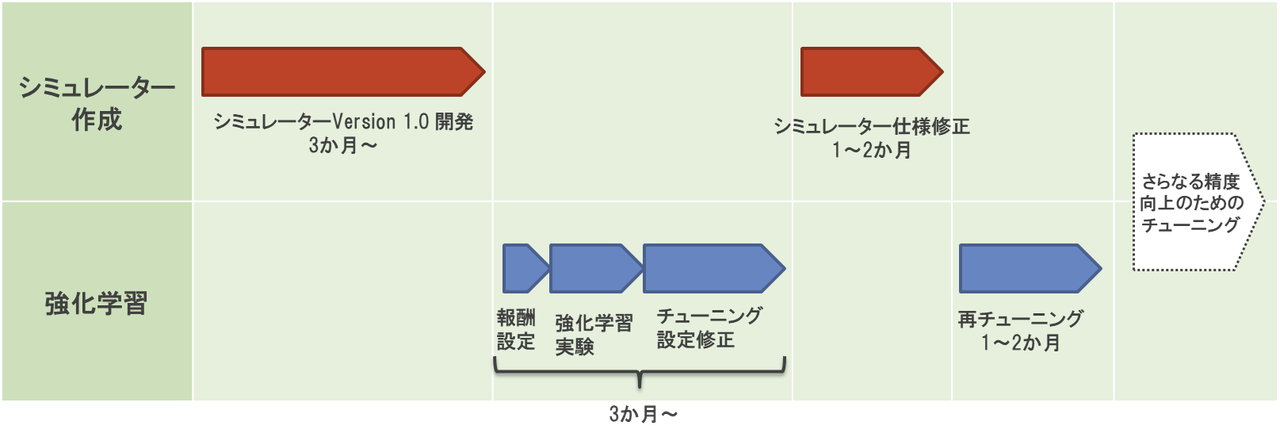
松下 開発期間は問題設定によって大きく変わりますが、例えば生産工程のような検討するべき要素の多い問題だと、シミュレーターの開発に1年間程度、強化学習モデルの開発に1年間弱で、現場で使えるようになるまでトータルで2年間程度かかると思います。当然その間まったく結果が出ないわけではなくて、早い段階でプロトタイプを作成して一通り動かせるようにしてから、ブラッシュアップや工場の仕様変更の対応などを継続します。工程としては、以下のようなイメージです。
- シミュレーター Version 1.0 の開発:3か月~
- 強化学習:3か月~
- 報酬など問題設定確認
- 実装して最初の実験結果を出力
- チューニング・問題設定微修正
- シミュレーター仕様修正: 1~2か月
- 強化学習再チューニング:1~2か月
強化学習におけるポイントや苦労した点など
松下 先ほど述べましたように、まずはシミュレーションモデルを構築するのに比較的時間がかかります。最近ではデジタルツインというトレンドの下で工場内での出来事の多くがデータ化されていますが、製造する品種を交換する際のコスト(時間的コスト、直接的費用)の組み合わせや、構内の移動の時間・制限、人が介在する必要がある作業など、現場に詳細に確認するべきポイントもまだまだ数多いと言えます。
また、シミュレーションがどのくらい正確か、という観点での検討も必要となります。実際の操業との比較や、想定されるシミュレーションシナリオに対してモデルが妥当な応答を示すかの確認については、現場の感覚とすり合わせながら精査していくことが必要で、どうしても時間がかかるプロセスです。
強化学習モデルの作成においては、試行錯誤が相当量必要です。例えば表形式データの教師あり学習であれば初手に Gradient Boosting Decision Tree を使えばある程度高い精度の結果が出る見込みが高いですが、強化学習のアルゴリズムの初手はその域には達していないのが現状です。したがってモデル改善は必須の作業となりますが、そこにはさらに強化学習特有の難しさがあります。モデル改善のためにはモデルが適切な行動を選択できているかを調べていきますが、各行動が正解か否かの判別は簡単ではありません。「なんでこのタイミングで品種の切り替えをしているのか、もう少し継続して作ればいいのに」と一見して効率的でなさそうな挙動が、実は先々を見越して全体最適に向かっていることもあるからです。
強化学習の挙動が正しいかどうかを確認する方法として、ルールベースでシンプルに構築したロジックと比較することが多いです。ルールベースはいくつかの指標(納期が近く在庫が少ない商品からラインに投入する、など)を用いて優先順位をつけて工場内の行動を決定します。強化学習モデルがルールベースと大きく異なる意外な振る舞いをすると、どちらがより適切なのかと考え込んでしまうこともしばしばありますが、これまでの定石を外したAI将棋の打ち筋を研究するようで、私としては楽しい作業ではあります(いかんせん時間がかかってしまいますね)。
なお、理論的には計算資源をかけて学習させ続ければいつかは最適な強化学習モデルができるのですが、現実的な期間で開発するためには、実際の計算環境である程度の期間(数日程度を目安にする場合が多いです)で学習を完了させる必要があります。このために学習を効率的に進める必要があり、生産ラインの状態や各タスクの状態について、どう特徴量(入力層)に落とし込むか、という点が課題です。囲碁の場合は盤面を画像のような情報としてそのまま入力することでうまくいきますが、工場の場合すべての情報(各製品の待機状況、必要量、納期、ラインの処理状況、などなど)をそのまま数値化すると囲碁・将棋と比べるとはるかに高次元な問題になってしまいます。効率良く学習するために、重要そうな情報のあたりを付けて人力によって特徴量エンジニアリングをしていきます。特徴量エンジニアリングについては、ひとつひとつ人が特徴量を変えて試してみて、結果をみてからまた調整を行うといった、地道な作業になります。コンピューターの性能がさらに飛躍的に向上すれば、すべての情報を投入して機械に任せるだけで済むようになる可能性もありますが、当面はこのような作業が必要なのかなと想像しています。
出来上がった強化学習モデルを現場での運用する際の注意点はありますか?
松下 運用に耐えられるものかどうか、という点で慎重に試験を行います。細かい個々の振る舞いで、何かおかしい判断はないかという点においては開発段階にて充分につぶしておくことが大切かなと思います。個々の振る舞いが正常であるということが確認できたら、1日を通して納期厳守やスループットが良好であるかという点で評価を行います。割り込み発注対応やトラブルなどもありますので、半日経過後に再評価というのも重要な確認です。
こうした評価を経て、お客様の自動プランニングシステムの一機能として導入いただいています。お客様によりますが、シミュレーション結果の多くをプランとして採用いただくこともありますし、製品の投入タイミングのみを採用いただくということもあります。工場の制御システムとの連携の兼ね合いもありますので、ケースバイケースですね。
幅広い業界で活躍する強化学習のユースケース(活用事例)
強化学習の問い合わせはどういう背景が多いですか?
松下 FA を目的とした取り組みの一環として、という流れがここ最近では多いです。工場以外では人流系・マーケティング系のお問い合わせも増えていますが、実現が難しいケースが多いイメージを持っています。強化学習を行うためにはシミュレーションが必要になります。対象がモノ・機械である工場のシミュレーションモデルは、人の移動・消費行動・戦略といった行動に比べると表現しやすいため相性が良いと思います(それでも工場のシミュレーションで半年、1年とかかるのですが…)。
工場以外で強化学習向きなテーマはありますか?
松下 工場以外でも、シミュレーションモデルが構築できる様々な分野で強化学習のユースケースが存在します。代表的なユースケースとしては以下のようなものがあります。
流通・小売・マーケティング分野
- ダイナミックプライシング: 需要と供給の変動に応じて、収益が最大化する最適な価格をリアルタイムに提案します。
- 施設内サイネージの最適化: お客様の混雑状況等に合わせて、表示するコンテンツをリアルタイムに制御します。
運輸・物流分野
- 配達のルーティング: 交通量や配送先の状況から、次にどこへ向かうべきか最適なルートを提案します。
- 自動倉庫内でのピッキング動線: 他の作業ロボットの位置を考慮し、渋滞を避けつつ最適となる動線をリアルタイムに制御します。
サービス・インフラ分野
- コールセンターの問い合わせ割当て: オペレーターのスキルや稼働状況に応じて、最適な着信割り当てを行います。
- テーマパークのアトラクション提案: 全体的な待ち時間が最小となり、顧客満足度が向上するような「次に乗るアトラクション」をアプリ等で提案します。
今後チャレンジしていきたいというものがありますか?
松下 技術的な観点ですと…、手掛けてきた多くの問題がシングルエージェントシミュレーションモデルで表現可能であったため、今後はマルチ-エージェントの強化学習にチャレンジしてみたいです。例えば製造業だとそれぞれタスク(目的)が違う複数のロボットを強化学習で行う場合には、マルチエージェントシミュレーションになります。
松下 それに限らず製造業での生産工程に関して、より実績を積んで皆様が気軽に強化学習を使えるように技術ナレッジを積み上げていきたいと思っています。
NTTデータ数理システムの強化学習における強み
シミュレーションと機械学習に関する豊富な経験と実績
松下 NTTデータ数理システムでは、シミュレーションや機械学習を活用した多くの企業の受託開発案件に携わってきました。また、シミュレーションツール S4 Simulation System の開発やお客様への導入支援でも実務へのシミュレーション適用技術を磨いています。
アカデミック分野の方々とも積極的に関わっており、機械学習関連は NeurIPS、ICML、その他国内の学会などで、シミュレーション関連は計測自動制御学会、日本オペレーションズ・リサーチ学会、経営情報学会などで当社社員が発表を行っています。感染シミュレーションでは筑波大学の倉橋先生に S4 Simulation System をご活用いただいていますが、最近 NHK やその他ニュースで取り上げられて注目されていますね。
筑波大学 倉橋様:社会シミュレーションによる新型コロナウイルス感染予防策の研究事例
松下 当社にお問い合わせいただく方は、Web検索やセミナーなどを通じて当社を知っていただくケースの他に、繋がりのあるアカデミック分野の先生や過去に一緒にお仕事をした企業の客様から当社をお客様にご紹介いただくケースもあります。当社の活動や仕事内容にご納得いただけた結果だと思いますので、大変ありがたいですね。
S4 Simulation System の活用について
松下 一からフレームワークなしでシミュレーターを作るのは大変なので、S4 Simulation System は工数の短縮に貢献できると思います。シミュレーションに必要不可欠なスケジュール管理機能や、様々なシミュレーションモデルに適用可能な汎用的な処理等、シミュレーターとして必要な機能はすでに組み込まれているため、シミュレーター開発時には、シミュレーションモデルの開発に注力することができます。
ソフトウェアとして品質を担保していますので、スクラッチでの開発に比べてテスト工数削減・品質保証の観点でもメリットがあります。また、標準で強化学習機能も組み込まれていますので、強化学習に必要な観測値や報酬値の定義、アルゴリズムやパラメータを設定するだけで、S4 Simulation System単体で強化学習機能を使用することも出来ます。
S4 Simulation System は Python ベースのシミュレーターです。Pythonプログラムから API として呼び出すこともできますし、S4 Simulation System から Python の豊富なライブラリを呼び出すこともできます。強化学習をはじめ、Python の様々な機械学習ライブラリと連携させる場合にも S4 Simulation System は親和性が高いシミュレーターですので、おすすめできます。
おわりに
今回は、「S4 Simulation System」を活用していただいた事例についてご紹介しました。シミュレーションの活用について、少しでも興味をお持ちいただけたでしょうか?
▼複雑なモデルをGUI上で表現し、シミュレーションを行なえる
S4 Simulation Systemについてはこちら
https://www.msi.co.jp/solution/s4/top.html
強化学習をはじめとして、機械学習やシミュレーションなどの技術活用のご相談も歓迎です。「データはあるから何となく何かをやりたい…」というきっかけでも大丈夫です。お客様が解きたい課題を弊社技術スタッフが一緒に課題整理を行いながら、ご要望に合わせたご利用形態で課題解決をサポートします!ぜひお気軽にお問い合わせ、ご相談いただけると幸いです。











