- HOME
- ディープラーニングでできることとは?メリット・機械学習との関係や少量データでの実現方法

更新日:2025年4月30日 18:05
公開日:2020年5月19日 19:30
ディープラーニングとは
ディープラーニング(Deep Learning)とはニューラルネットワークを発展させた機械学習手法です。 人間の脳の情報伝達はニューロン(神経細胞)の樹状突起と軸索での電気信号の伝達と、その間のシナプスによる神経伝達物質による化学信号の伝達で行われています。
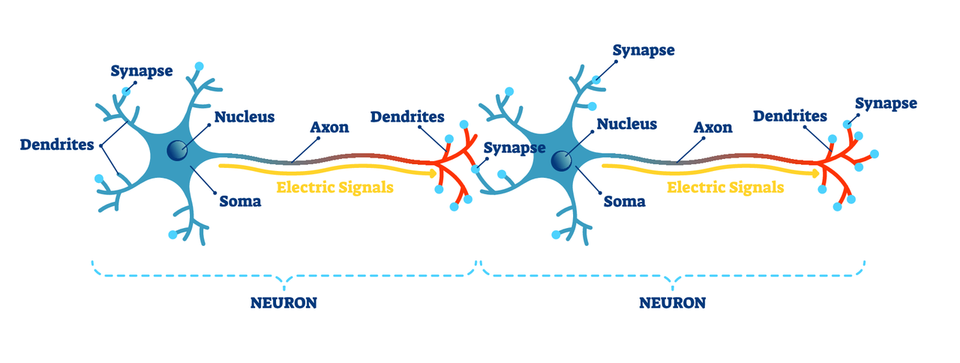
この構造を模したものがパーセプトロン(Perceptron)です。 入力として電気信号を模した情報を受け取り、重み付き和が一定のしきい値を超えなければ0(もしくは十分に小さな値)、しきい値を超えると1(もしくは十分に大きな値)という、次の神経に電気信号を伝えるかどうかを模した情報を出力します。 古典的なパーセプトロンでは入力も出力も0または1のみですが、パーセプトロンを複数組み合わせて複雑な処理を学習させるためには計算しやすいように下図のような0と1以外の値も許すような構造にします。
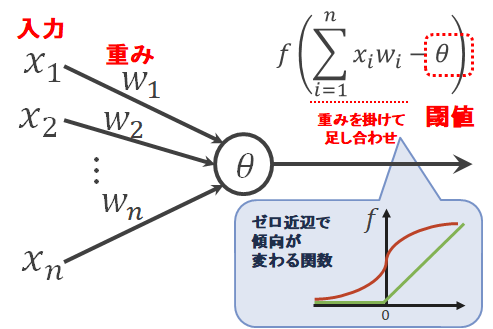
1つのパーセプトロンではかなり単純な処理しかできないことが分かっており、人間が行うような複雑な処理を実現するには複数のパーセプトロンを組み合わせる必要があります。 このパーセプトロン(もしくはその他の人工ニューロン)の組み合わせの構造(モデル)そのもの、およびその構造でうまく情報を学習させる手法の研究がニューラルネットワーク(Neural Network)です。
多層パーセプトロンと呼ばれる下図のような層構造をとると効率的に学習ができることが分かっており、実用的に使われているニューラルネットワークのほとんどがこの多層パーセプトロンをベースにしたモデルです。
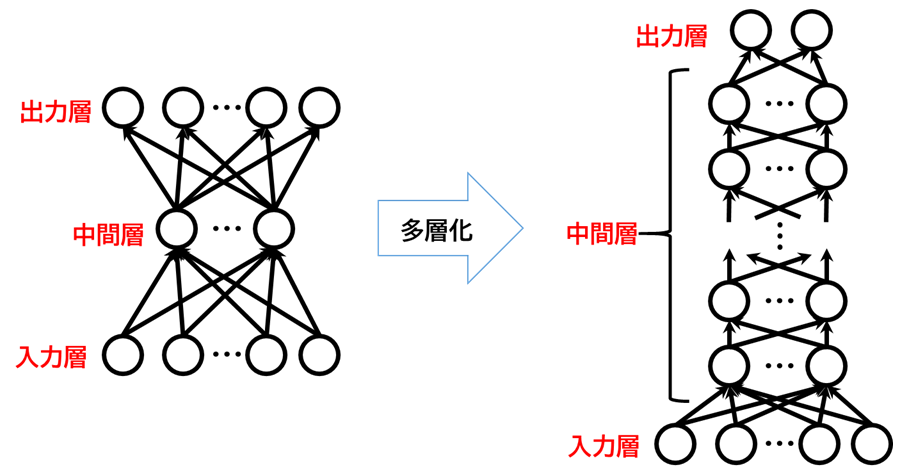
かつては中間層として多くの層を重ねるとうまく情報を学習させることができなかったため、上図の左のような3層のニューラルネットワークが主として使われていましたが、研究が進みうまく学習させる技術が発達してきたため、現在では上図の右のようなイメージの中間層の深いニューラルネットワークが使われるようになりました。 上図の右のような中間層の深いニューラルネットワークをディープラーニング(Deep Learning)と呼ばれます。
現在使われているディープラーニングモデルの内部パラメータ数は数千万になることもあり、機械学習の様々な手法の中でも極めて多いと言えます。機械学習における学習とは、学習データに適合するようにこのパラメータを調整することに他なりません。パラメータ数が多いほど学習データの細かい情報を反映した表現力の高いモデルを作ることができます。
一般にモデルのパラメータ数が(学習データと比べて)多い場合、学習データに過剰適合(オーバーフィッティング)してしまい、未知データに対する推論の精度が下がりやすいこと(汎化性能の低下)が知られています。 機械学習の領域では、この問題を過学習と言います。 この原因としては、表現力が高いモデルでは学習データのノイズなどの本質ではないばらつきにも追従しやすくなることなどが挙げられます。 ニューラルネットワーク自体のアイデアは以前からありましたが、この過剰適合の問題がネックとなって層の数を増やして精度を上げることができていませんでした。 しかし2012年頃にこの問題を上手く避けて学習を進める技術(ドロップアウト、近年ではバッチ正規化(Batch Normalization)など)が開発されたことで、現在のように非常に多層のモデルで高精度な推論を行うことが可能になりました。

ディープラーニングの応用例
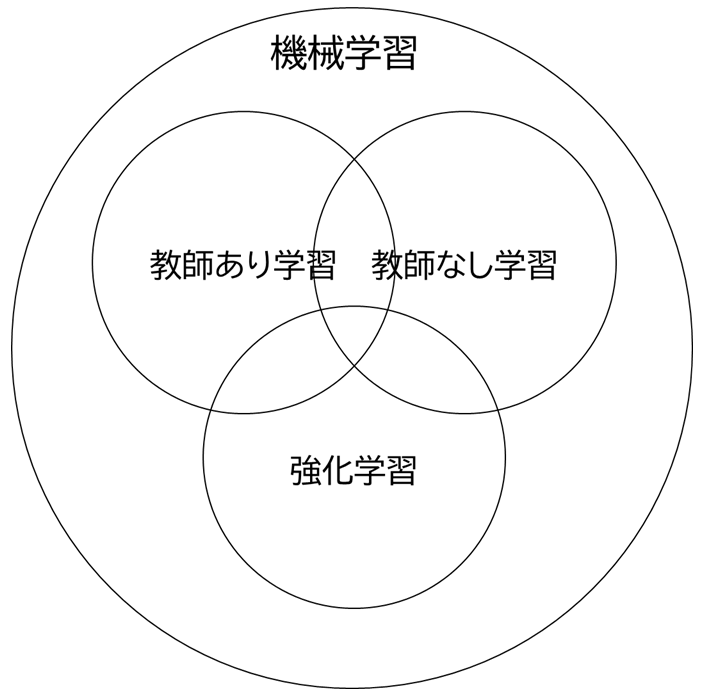
機械学習の代表的な枠組みとして教師あり学習、教師なし学習、強化学習という3つの分野があります。 機械学習の手法(SVM、K-means など)は典型的にはいずれか1つの枠組みの中の含まれるもので、従来はディープラーニングも教師あり学習の手法の1つとして認識されていたはずです。
2012年頃からのディープラーニングブームの中で、これまで機械学習で解決するのが難しいとされたきたタスクがディープラーニングで解決できるということが分かり始めました。 様々なタスクへの応用が広がり、教師あり学習以外の枠組みでもディープラーニングのアイディアが活用されるようになりました。 現在では単なる教師あり学習の一手法ではなく他の枠組みでも活用される汎用的な技術と認識されており、「既存の手法をディープラーニング要素を組み込んでみたら精度が上がりました」という報告が盛んに行われています。
機械学習の代表的な枠組みである、教師あり学習、教師なし学習、強化学習について主な応用先を紹介します。
教師あり学習
教師あり学習は学習データに対応する正解ラベル(入力データとそれに対応するラベル(タグ)などの出力値)がある場合に利用できる手法です。 正解ラベル付きのデータに関する学習を行うことで、未知の入力に対しても正しい 出力値を推論(予測)できるようになります。 品質の高いモデルを作成しやすい問題設定で、現時点で実用的に使われているディープラーニングモデルの多くが教師あり学習の枠組みに含まれます。
画像、動画系
画素の空間的な構造に意味があるため、CNN(Convolution Neural Network、畳み込みニューラルネットワーク)によって特徴量を抽出するモデルが多く用いられています。以下の3つのタスクが代表的です。後のものほど詳細な情報を得られますが、学習データとして細かい情報を与える必要がありデータの準備が大変になります。
- 画像分類:画像に何が写っているか当てる。
- 物体検出:画像のどこ(矩形単位)に何が写っているか当てる。
- 画像セグメンテーション:画像のどこ(画素単位)に何が写っているか当てる。
NTTデータ 様:画像認識・分類技術による製品管理・分類業務の自動化事例
時系列、音声、テキスト系
値の時系列的な変化、語や音素の前後関係に意味があるため、RNN(Recurrent Neural Network、再帰型ニューラルネットワーク)によって特徴量を抽出するモデルが多くあります。以下のような例があります。
- 質問応答(Siri、スマートスピーカー、チャットボット)
- 自動翻訳
- 情報検索(検索エンジン)
- 文字変換(IME)
マルチモーダル
上記のデータを複数種類入力して学習する手法です。各データの特徴量をそれぞれ抽出し、それらを統合したデータに基づいて判断を行います。 ディープラーニングモデルは層構造の設計の自由度が高く、下図のような画像入力層の CNN とテキスト入力層の RNN を組み合わせたモデルも自然に作れます(うまく学習させるためにはそれなりに工夫が必要ですが)。 次のような応用例が考えられます。
- 画像、センサー時系列、音声を組み合わせた設備の異常検知
- 画像、テキストを組み合わせたECサイトの商品分類、商品評価
人間が何かを判断するためには五感をフルに活用しているはずで、ディープラーニングモデルでも同様に様々なチャネルのデータを使用することで、より高精度なモデルができるはずだというのはとても自然な発想です。 一方で、人間の持つ、不要な情報を認識から除外する能力というのは非常に強力で、ディープラーニングモデルに人間が判断する際と同じような感覚で役に立つかどうかわからない情報も与えてしまうと、手間が増えるだけでかえって学習効率が悪くなる場合もままあります。 とりあえずデータがあるから全部使ってみようではなく、目的に対して意味のある情報だから使ってみようという考え方が重要です。 "Garbage in, garbage out" の原則に立ち返りましょう。
教師なし学習
教師あり学習にある正解ラベルが存在せず、データだけがある状況で行う学習です。 データは大量にあるが正解ラベルはついていないというケースは非常に多いですが、このような状況でも何らかの学習ができるという点で非常に魅力的な枠組みです。 ただし、一般的に教師あり学習よりも難しいタスクになりやすい点や、モデルの良さを定量的に評価する指標を作ることが難しい点、モデルのアウトプットが直接の問題解決にならない場合もあるという点に注意が必要です。 精度を求めるのならば、コストをかけても正解ラベルをつけて教師あり学習の枠組みで解決した方が、現実に即した解決策になることも多いです。
生成モデル
学習データの特徴を学習し、学習データによく似た偽物のデータを生成するモデルです。 偽物のデータを作ってどう役に立つのか分かりにくいですが、例えば画像データに対する生成モデルを応用することで、画像の高解像度化、マスクなどで一部が隠された顔画像から素顔の(ような)画像を生成するなどの処理が実現可能です。
用いられる手法としては GAN(敵対的生成ネットワーク)が有名です。 これは、2つの敵対するネットワークを交互に競わせながら学習させる技術です。 一方のネットワーク(Generator)はできるだけ本物に似せた偽物を生成し、もう一方(Discriminator)のネットワークはそれを見破ろうとします。
それぞれ紙幣の偽造を行う犯人と、それを見破ろうとする警官で例えられます。 この過程で見破られにくい本物らしさを学習することにより高品質なデータ生成が可能になります。
参考記事
当社の社員が cycleGAN の実験をした記事です。
GAN で犬を猫にできるか
異常検出
教師あり学習の枠組みで異常判定を行うためには異常データも大量に入手出来ていることが求められます。 しかし、多くのケースで異常データというのはごく少量しか入手出来ていないため、このような枠組みではやりたいことが実現できません。 逆に入手出来ているデータのほとんどが正常データであるという仮定の下に、データから正常とは何かを抽出し、そうではないものを異常だと考えようというのが教師なし異常検出の考え方です。
従来から様々な手法が提案されていますが、ディープラーニングを活用したモデルとして VAE、ディープメトリックラーニングなどが近年話題になっています。 教師なし異常検知全体の課題として、センシティブな調整が必要な点があり、時間をかけた一点物開発になってしまいがちです。ニーズが多いことも確かで、NTTデータ数理システムでは、その経験を異常検知パッケージに集結させる取り組みを行っています。
強化学習
強化学習の目的はエージェントがとり得る選択肢の中から、将来的により良い報酬を得ることに向けてより良い判断を自動でできるようにすることです。
エージェントが取る行動に対してどのような環境変化が起きるか、というシミュレーションと、将来価値を見越して最適な行動を選び取る最適化をまさに組みあわせた手法です。
1980年代から研究が盛んに行われている手法ですが、現在の状態から得られる将来価値を表現する関数(価値関数)、行動に対する将来価値を表現する関数(状態行動価値)、施策を与える関数(方策関数)、に対して多層のニューラルネットワークを用いることで精度が飛躍的に高められることがわかりました(DQN、DDPG、TRPO、A3C など)。
次のような応用例があります。
- 囲碁AI
- 自動運転
- 生産設備自動制御
- 超高層建物の揺れを深層強化学習AIで制御(事例記事)
必要なデータの規模感
2012年に ILSVRC2012 という画像認識のコンテストが行われ、ディープラーニングを用いるモデルである AlexNet が画像分類(画像に写るものが何か当てる)の部門で優勝しました。 このモデルの誤認識率は16.4%で、前年の25.8%を大きく下回りました。 さらに2015年のコンテストで優勝した ResNet の誤認識率は3.57%でした。 この問題における人間の誤認識率は5%程度と言われており、人間を上回る精度を達成したということで話題になりました。 これらの学習や評価に用いられた画像枚数は以下の通りです。
- 学習用画像:120万枚、つまり1種類(クラス)あたり1,200枚
- 検証用画像:5万枚
- 評価用画像:10万枚
これらすべての画像に写っているものが何か(ダルメシアン、飛行機、城など)という1,000種類(クラス)の正解ラベルが付けられています。 人間の認識精度に勝ったといっても、これだけ大量のデータを学習した結果だということには注意する必要があります。 ディープラーニングで何かをやりたいと言われると、数百万件~数千万件程度のデータは必要になる場合が多く、学習データの入手が可能かどうかが実現性を左右するファクターとなります。
少量のデータでもディープラーニングを実現するための技術
私たちが企業の方から予測モデル作成などのご相談をいただく中では、これだけの学習データを用意することは難しいことがほとんどです。 既に学習済みのモデルを用いて提供されているサービスでやりたいことが実現できないか、データ取得が可能かつやりたいことが実現できるような問題設定をうまく設計できないかという検討が根本的に重要ですが、どうしても少ないデータしか得られない状況でモデル作成を行わなければいけないというケースも存在します。 このような状況に対処する枠組みとして、下記のようなものが考えられています。
転移学習(Transfer Learning)
転移学習とは、既存の学習済みモデルを出発点として、新しく与えた学習対象のデータを学習させる枠組みです。 新しいデータで予測したい問題設定と、既存の学習済みモデルの問題設定が大きく違わなければ、少量のデータでも高精度なモデルを作ることができます。 計算は新しい学習データだけで行えば良いので、計算時間が短くて済むというのも大きなメリットです。
ディープラーニングモデルの入力層側のネットワークは既存の学習済みモデルの情報をそのまま使用し、出力層付近のネットワークを問題設定に合わせて作り直して、作り直した部分だけ新しいデータで学習させるというのが典型的なやり方です。 画像やテキストデータでは、精度の高い既存の学習済モデルを汎用的な特徴量抽出器として用いることができるので転移学習がしやすいと考えられており、転移学習するために有力な学習済みモデルが公開されています。 特にテキストデータに対する事前学習モデルの BERT が転移学習させた多くのタスクで高い精度を達成して話題になりました。
Few-Shot Learning
一般的な転移学習では少量データで学習が可能とは言いながらも、数百から数千程度のデータが存在することが期待されます。 分類タスクにおいて、さらに極端に数件のデータでデータ学習ができるようにすることを目指すのが Few-Shot Learning の枠組みです。 特に1件のデータだけで学習させる場合、One-Shot Learning と呼ばれます。
メタ学習という考え方で数件のデータでもうまく学習が進むような学習の仕方自体を学習させる方法が提案されており、特に画像データに対してはたくさんの報告があります。
半教師あり学習
使えるデータは大量にあるものの、正解ラベル付きデータは少量しか存在しないという問題設定は現実によくあります。 このような問題設定の枠組みとして半教師あり学習というものがあり、様々な手法が提案されています。
参考記事
当社の社員が Ladder Network の紹介をした記事です。
Deep Learning は半教師あり学習で簡単になる
説明可能な AI?
ディープラーニングを実用する際の課題として、内部がブラックボックスでどうしてそういう出力が得られたのかを人間が理解することが難しいという点がよく挙げられます。 しかし、ディープラーニングモデルが予測する際のロジックは明確に数式で書き下されており、人間にとって理解しにくいのは事実ではありますが、人間の脳内と比べれば相対的にホワイトボックス的ではあります。 ブラックボックスであるという指摘に対してどのように立ち向かうべきなのでしょうか。
人間の判断に対してブラックボックスだから使えないという指摘がないのは、おそらく人間は説明を求められた際に何らかの「言い訳」を工夫する術を心得ているためと考えることができます。 ただしこの言い訳はまず間違いなく脳神経の働きを説明するものではないでしょう。 同じ理屈で考えて、ディープラーニングモデルに求められる言い訳も予測ロジックの説明ではなく、入力と出力のシンプルな対応関係ということになりそうです。 典型的には入力として与えた大量のデータのうち、どのデータや特徴量が判断に強く影響を与えたのか、与えた影響を簡単な関係にするとどのようなものになるか、という情報を得ることができます。 このような要求に対しては、近年 XAI(Explanable AI)と言われる分野などで盛んに研究が行われており、タスクによっては直感的に分かりやすい説明ができる仕組みが提案されています。 ただし、基本的にはディープラーニングモデルの入出力に対する説明であって、入力として人間が解釈しにくいデータや出力との因果関係がよくわからないデータを投入してしまえば、どうしても人間には理解しにくい説明になってしまう点には注意が必要です(実際に「使えるかどうかよくわからないけど入れてみたら精度が上がった」というようなケースもままあり、運用に向けた説明の際に困ったりします)。
本質的にディープラーニングモデルそのものの説明可能性が求められるのであれば上記のような検討を行うことになると思いますが、ビジネス活用という観点では実はディープラーニングモデルそのものに対する説明を求められているとは限らないかもしれません。
ビジネス活用の際の説明可能性を考えるためには、「なぜ説明が必要なのか?」を、業務観点の要求をきちんと理解して、しかるべき手を打つということが重要です。
例えば、「法的に(モデルの欠陥について)問われた際の申し開き(言い訳)が必要だから説明が必要」と相談を受けたことがあります。 掘り下げて検討した結果、「どういったケースでどういったテストを行って、運用の可否を判断したのか」という点がこのケースにおいては法律的に強力なステートメントになる、ということが分かりました。 検討に当たって最も現実に即したアドバイスを頂けたのは AI の専門家ではなく、法律の専門家である弁護士さんでした。
この話は特殊なケースかもしれませんが「説明可能な AI が必要と思われたが、本当に大事なのは十分なテストケースであった」という状況は他のケースでもあり得そうです。 AI というとアルゴリズムに閉じた世界での検討をしてしまいがちなのですが(技術検討シーンではよいのですが)、業務活用のシーンではきちんと業務上のリクエストに耳を傾けて論点の整理、課題の解決をしていくことも重要です。
おわりに
ディープラーニングは非常に強力な手法で、特に画像データやテキストデータの分析では大きな成果を上げています。 これまでできなかったことができる、という点でつい効能が潤色されてしまいがちですが、得られる入力と期待されている出力を見極めた上で、様々な機械学習手法の中の1ジャンルということは意識した上でディープラーニングを使うべきかを判断する必要はあります。
- よりシンプルな手法で必要な精度を達成させることができないか(ディープラーニングは大量のデータが必要で計算時間もかかるため、もっとシンプルな手法で解決可能な場合はその方が望ましい)
- 網羅的で十分な量のデータを用意できるのか(例えば画像分類なら問題にもよるが1ラベル当たり数百枚はデータがあることが望ましい)
- 課題についての知見が残らなくても良いのか(ルールや特徴量を人間が設計する手法では要件定義を十分に行う必要があり、この過程で人間が課題についての理解を深められる場合がある)
- モデルが間違った結果を出してもカバーする体制で運用できるのか(精度が高いとは言っても100%にはならないので間違える可能性を見込んで手当しておく必要がある)
ディープラーニングに限りませんが、ビジネスでのデータ活用ではできるかぎり問題設定をシンプルかつ効率的に実現することが非常に重要です。 NTTデータ数理システムにはビジネスの現場でディープラーニングなどの技術を生かすことに長けた技術者が多く在籍しておりますので、「これってディープラーニングでやるのがいいのかな?」「もっと良いやり方や事例はないのかな?」などお悩みのことがあれば、ぜひお気軽にご相談ください。
また当社では、数値データだけでなくテキストデータでもディープラーニングのモデルを簡単に作成することのできる Alkano という製品をご提供しています。









