- HOME
- 連合学習とは?Federated Learningの基礎知識をわかりやすく解説

更新日:2024年11月 6日 15:50
公開日:2022年7月20日 13:00

この記事では、Google が2017年に提唱して以来大きな注目を集めている技術である連合学習(連携学習、フェデレーテッドラーニング)について、
- 連合学習とは何か
- 典型的なユースケース
- 連合学習における課題とそれに対するアプローチ
を紹介します。
連合学習とは何か
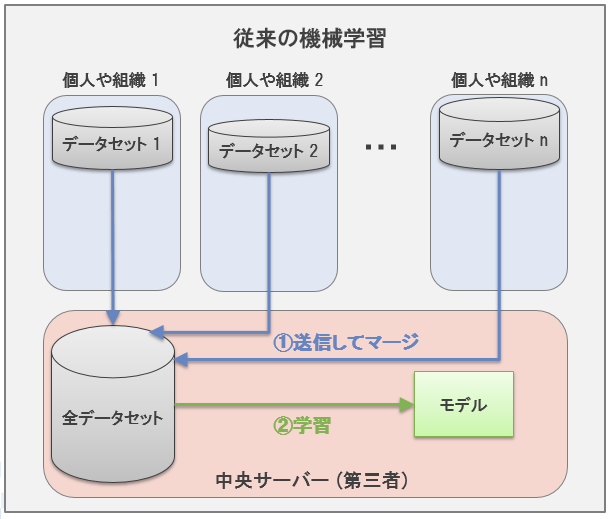
連合学習は、学習データセットが分散している環境での機械学習モデルの汎用的な学習法の一つです。一般に機械学習における成功のカギはなるべく多くのデータをモデルに学習させることです。従来の機械学習では、下図のように分散している学習データセットを初めに一つの大きなデータセットに集約し、それから機械学習モデル (例: 線形回帰モデル、深層ニューラルネットワーク) を学習するということを行ってきました。
これに対して連合学習では、まず(従来の機械学習と同様に)1つの機械学習モデルを選択し、それから下図のように分散している学習データセットを分散させたままモデルを学習させます。
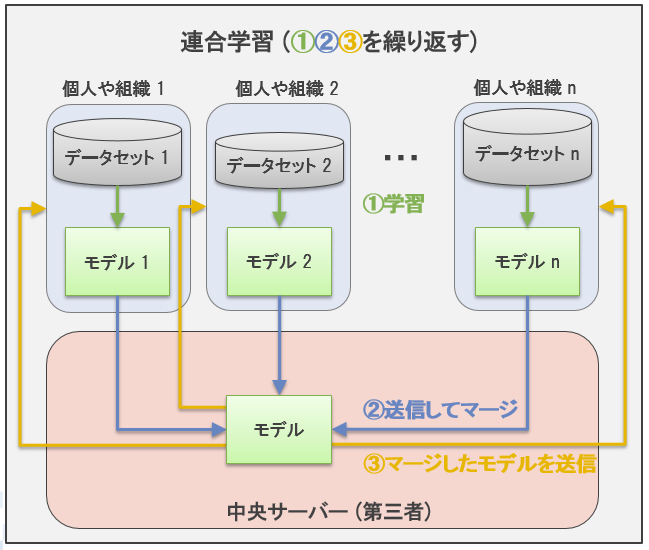
この二つのアプローチの重要な違いは、各個人や組織(一般にクライアントと呼びます)の所有している生のデータセットを中央サーバーに送信する必要があるか否か、という点です。この違いが重要となる例として、データセットに個人情報が含まれているケースを考えてみましょう。従来の機械学習では中央サーバーに個人情報が含まれるデータセットをそのまま送る必要があり、これはプライバシー保護の観点で望ましくありません。一方で連合学習では生のデータセットを他者に送る必要はなく、各クライアントが学習した機械学習モデルのみを送れば十分です。
それでは、連合学習を使うことによって従来の機械学習と比べてモデル精度が損なわれることはないのでしょうか。実は、連合学習のプロセスを繰り返して得られるモデルの精度は従来の機械学習で得られるモデルの精度と一致するということが(いくつかの仮定の下で)理論的に示されています。また実験的にも、連合学習によって得られたモデルの精度は従来の機械学習によって得られたモデルの精度と比べて遜色がないこと、および各クライアントが自身の所有するデータセットだけで学習したモデルよりも高精度であるという結果が多数報告されています。
このように、従来の機械学習ではセキュリティ上利用が難しかったシーンであっても、連合学習を利用することで分散したデータセットによるモデルの学習が可能になります。またセキュリティの問題以外にも、データセットのサイズが大きいために集約することが物理的に難しい、といった場合にも、連合学習によってモデル学習が可能になります。
連合学習の典型的なユースケース
連合学習は、ユースケースによって
- クロスデバイス(Cross-device)学習
- クロスサイロ(Cross-silo)学習
の二つに大別されます。
クロスデバイス学習
クロスデバイス学習での典型例は、各クライアントがスマートフォンのような IoTデバイスであるケースです。例えば、Google は各スマートフォンユーザーの予測変換履歴から連合学習を用いて予測変換モデルを学習させています(Federated Learning: Collaborative Machine Learning without Centralized Training Data)。各ユーザーの予測変換履歴は非常にプライベートな情報と考えられるため従来型の学習法では取り扱いが困難でしたが、連合学習を用いることで初めてプライバシーを守りながら学習を行うことが可能となりました。
クロスサイロ学習
クロスサイロ学習での典型例は、各クライアントが互いに提携している病院などの組織であるケースです。各病院のもつ患者情報 (CT 画像や電子カルテなど) を用いて機械学習モデルを作成する際には、プライバシー保護の観点から患者情報を互いに共有できないことが実施における障害となります。このような場合であっても、連合学習によりモデルの学習が可能になります。例えば、NVIDIA は実際に20の医療機関のもつ胸部 X 線やバイタル情報、臨床検査値等を用いて COVID-19 に罹患した患者の酸素投与判断モデルを連合学習を用いて構築しています(Hospitals Build AI Model that Predicts Oxygen Needs of COVID-19 Patients | NVIDIA Blog)。その他にも、複数の金融機関が共同で不正送金検知モデルを構築する際に連合学習が使われた事例もあります。
連合学習における課題とそれに対するアプローチ
重要な課題として、 次の4つの課題があると考えられます:
- 通信量の削減
- プライバシー保護の保証
- 頑健性の保証
- パーソナライゼーション
1. 通信量の削減
連合学習における大きな問題点として、学習時に各クライアントは自身のデータセットで学習したモデルを繰り返し中央サーバーとやり取りする必要があり、通信コストが高い、ということがあります。特に近年よく利用される機械学習モデルである深層学習モデルの場合には、モデルサイズが非常に大きくなりうるため、この問題はより深刻になります。さらに、通信するモデルの暗号化等も通信量の増大につながります。
そのため、モデルの学習に必要な通信回数が少なくて済む効率的な連合学習アルゴリズムの研究が現在まで盛んに行われています。本記事の執筆者は、この方向での研究を行い、執筆論文が機械学習のトップカンファレンスの一つである ICML2021 に採択されました(Bias-Variance Reduced Local SGD for Less Heterogeneous Federated Learning)。この論文で提案しているアルゴリズムのアイディアは次のようなものです:
2. プライバシー保護の保証
連合学習の大きな利点は、各クライアントのデータセットを共有することなしにモデルの学習を行える点です。しかし、各クライアントが共有した学習モデルから学習に用いたデータセットの情報は漏洩しないのでしょうか?
実は、共有した学習モデルから学習に用いたデータセットの情報を窃取する復元攻撃(reconstruction attack)と呼ばれる技術が知られており(Deep Leakage from Gradients)、より安全な学習のためには、連合学習においても各クライアントが共有した情報からデータセットの情報が漏洩しないことを保証する必要があります。
共有した情報からのデータの漏洩のしにくさを定量的に評価する方法として差分プライバシー(Differential privacy)という概念が広く用いられています。直観的には、データにあらかじめノイズを足してから共有する、ということを行った場合のデータの漏洩の起こりやすさを評価するものです。連合学習では、学習アルゴリズムは差分プライバシー保証があることが望ましいと考えられています。
3. 頑健性の保証
連合学習におけるもう一つの問題として、学習に参加している一部のクライアントが悪意をもって実際の学習モデルと異なるモデルを送信した場合、学習全体が崩壊してしまう、ということが挙げられます。例えば、cross-device学習のスマートフォンの予測変換モデルの例では、あるユーザーがでたらめな予測変換履歴を使用した場合に、全体の学習モデルの精度が劣化することが予想されます。
分散コンピューティングにおいて、ある一部のクライアントが(中央サーバーに気づかれずに)異常な行動をしたとしても、全体の処理は変わらず上手くいくという頑健性が重要になりますが、これをビザンチン耐障害性(Byzantine fault tolerance)と呼びます。
連合学習でもビザンチン耐障害性を持つことが重要で、盛んに研究が行われています。基本的なアイディアは、中央サーバーが各クライアントの送信モデルを集約する際に「異常値を除く」というものです(Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates)。例えば1次元データの平均値の頑健な推定量として中央値がよく利用されますが、この考え方を一般化したものと捉えることができます。
4. パーソナライゼーション(Personalization)
連合学習においては、各クライアントがデータセットを所有しており、それらのデータ分布は一般に異なります(これをバイアスと呼びます)。たとえ
具体的な方法は多数提案されており、例えば、各モデルがモデルのクライアント平均と離れすぎないような制約の下で個別モデルを学習する「正則化法」、モデルの一部のみをクライアント間で共有する「重み共有法」、メタ学習の分野で用いられている MAML(Model-Agnostic Meta-Learning)を連合学習に取り入れた「メタ学習法」などがあります。
実応用上は、必要に応じて上記4つの技術を組み合わせた連合学習アルゴリズムの構築が重要となります。
まとめ
この記事では、連合学習の基礎知識を簡単に紹介しました。連合学習は、分散しているデータセットを集約せずに機械学習モデルを学習することを可能にし、金融、医療、IT・通信など様々な分野で企業が応用し成果を上げています。しかし、本記事で紹介したような様々な課題が残っており、それらを克服する技術の研究開発・応用が進んでいます。
NTTデータ数理システムでは、IT・通信分野のお客様への、差分プライバシー技術を活用したプライバシー保護保障つきの連合学習アルゴリズムの研究・開発支援を行った実績もございます。研究開発、実務への応用などをご検討の方はぜひご相談ください。











