- HOME
- 深層強化学習を用いた組合せ最適化問題へのアプローチ

更新日:2026年4月30日 15:46
公開日:2023年5月29日 17:00

巡回セールスマン問題やスケジューリング問題などの組合せ最適化問題は、ビジネスの様々な局面で現れ、NTTデータ数理システムでも多数の案件を扱っています。
参考記事
難しくても使いこなす組合せ最適化
数理最適化を用いて配車計画システムに台数削減・自動化を実現した事例
組合せ最適化問題に対して最適解を高速に求めることは容易ではなく、したがって分枝限定法を始めとする様々な最適化アルゴリズムが研究されてきました。近年、深層強化学習の発展を背景に、深層強化学習を用いて組合せ最適化問題を解こうとするアプローチが研究されています。本記事ではこの新たなアプローチについて概説します。
強化学習による組合せ最適化ソルバの学習
強化学習はエージェントが試行錯誤を繰り返すことで望ましい振る舞いを学習する手法です。例えば囲碁や将棋といったボードゲームでは、エージェント同士で対戦を繰り返し行い良い手を学習させることで、人間のプロに勝つようなエージェントが作成されました。
組合せ最適化問題に適用する場合には、様々な問題例を繰り返し解く(※1)ことで良いソルバを学習します。ここでいう問題例とは、例えば巡回セールス問題であれば、具体的に定められた都市配置のセットのことを指します。問題例の作成にはデータベースから取得する・乱数生成するなどの方法が考えられます。運用時には、こうして学習されたソルバを実際に解きたい問題例に適用し解(※2)を求めます。
※1, 2 本記事では簡潔さを考慮し、最適性や実行可能性が保証されないような場合でも「解」および「解く」という表現を用います。
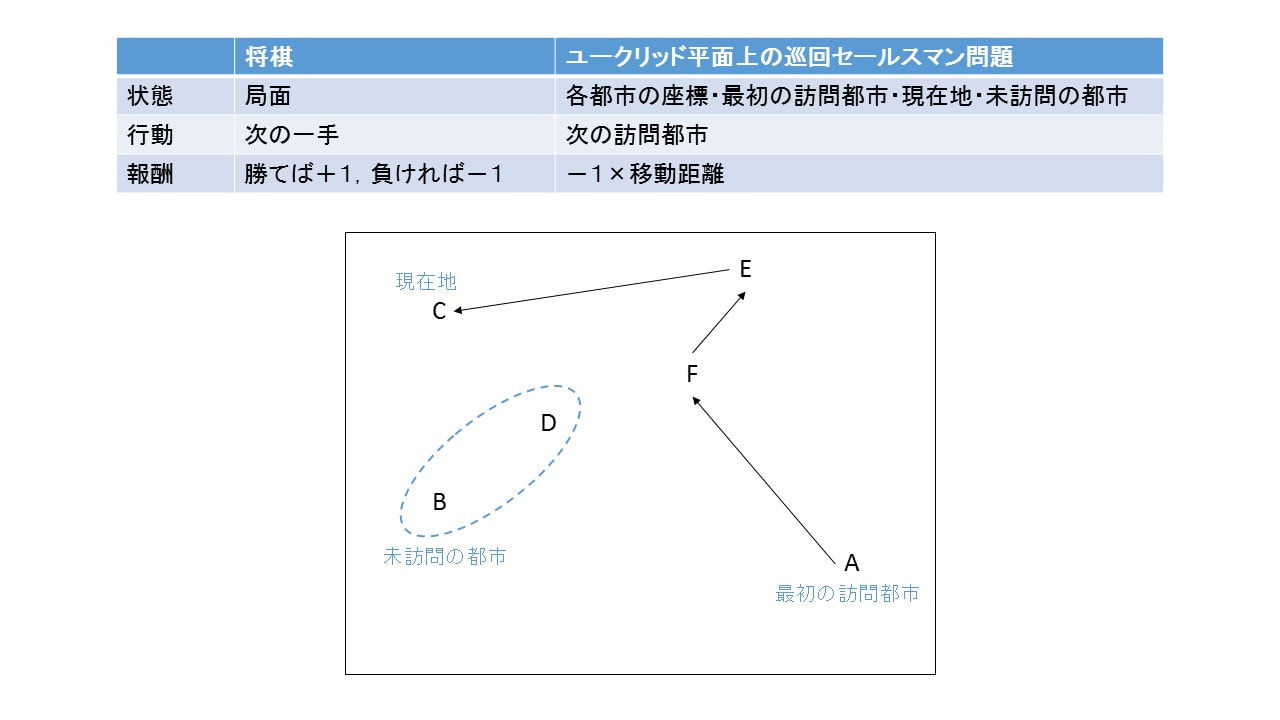
深層強化学習によるソルバの学習の具体例として、ユークリッド平面上の巡回セールスマン問題を考えます。巡回セールスマン問題では未訪問の都市の中から次に訪問する都市を逐次的に1つずつ選択することで実行可能解を求めることができます。得られる実行可能解の良し悪しは都市の選択をどのように行うかにより左右されますが、この都市選択を強化学習の行動とみなすことができます。状態・報酬も含めた定式化の例を図1に示します。この定式化のもとで深層強化学習を行うことで、状態を入力、次に訪問すべき都市を出力とするニューラルネットワークを得ることができます。
ニューラルネットワークをソルバのどの部分に用いるかにはいくつかの種類が考えられます[1]。先の巡回セールスマン問題の例では、1都市ずつではありますが、ニューラルネットワークを用いて問題例に対する解を直接的に生成しています。この場合、ソルバの演算はほぼニューラルネットワークの計算のみであるため、非常に高速に解を求めることができます。別の方法は、既存の最適化アルゴリズムの振る舞いの一部をニューラルネットワークで置き換えるものです。例えば、分枝限定法における変数選択をニューラルネットワークで実行する方法があります。この方法では高速化の程度は限定的と考えられる一方、アルゴリズムの大枠は人間が設計しているため出鱈目な解は生成されにくいという利点があります。そのほか、近傍探索のように解を逐次的に更新する際の更新規則をニューラルネットワークで表現するなどの方法もあります。
組合せ最適化問題に強化学習を適用するメリット
強化学習を組合せ最適化問題に適用するメリットには以下が考えられます。
一つは、すでに言及しましたが、計算の高速化です。通常の最適化アルゴリズムでは、解きたい問題例が与えられるたびにゼロから計算を始めるため、質の良い解を得るには相応の時間を要します。一方、強化学習を用いる場合は、学習には多大な計算時間を要するものの、解きたい問題例に対しては学習結果を適用するだけでよいため比較的短時間で実行することができます。
もう一つのメリットはより概念的なものです。多くの組合せ最適化問題は、問題の規模が大きくなると、最適解もしくは近似保証のある解を現実的な計算時間で求めることが難しいと予想されています。したがって、全ての問題例に対して万能に機能する最適化アルゴリズムの開発は恐らくできません。一方、現実に解きたい問題例は、数学的に存在し得る全ての問題例からするとごく一部であるかもしれません。強化学習では対象とする問題例のバリエーションを限定し、そこに特化して学習を行うことで、目的関数値の良い解を速く求めることを目指しています。もっとも数理最適化手法でも手元の問題に対してチューニングを重ねることで計算時間や解の質の改善を図ることは考えられます。強化学習によるアプローチは、このチューニングの作業をできる限り人の手を介しない汎用的な学習アルゴリズムで置きかえる試みともいえます。
応用に向けた課題
最後に強化学習を組合せ最適化問題へ適用する際の課題をいくつかあげます。
一つは複雑な制約条件を扱うことの難しさです。最適化問題は制約条件と目的関数とで記述されますが、強化学習には解の良さを表すものが報酬しかないため、制約条件を満たす解の発見そのものが難しい場合には、制約条件も報酬として表現する必要があります。素朴には制約条件を破った程度に応じて罰則、すなわち、負の報酬を与えることが考えられますが、実際にはそれだけでは学習が難しいことが経験的に知られています。また、複数の制約条件がある場合には罰則間で重みをどう調整するかも問題となります。こうした問題に対して、制約条件を満たす解の探索と目的関数値の良い解の探索とを分けて多段で学習するなどの対策が研究されています[2]。
もう一つの課題は汎化性能に関するものです。先に述べたように強化学習では学習に使う問題例のバリエーションをある程度限定することでソルバの性能向上を図っていますが、これは一方で学習時の問題例と大きく異なる問題例はうまく解けない可能性があるという欠点にもなります。例えば、巡回セールスマン問題において、学習時よりも都市数を増やすとうまく解けなくなるという事例が報告されており、どの深層強化学習アルゴリズムの汎化性能が高いかが実験的に調べられています[3]。
おわりに
この記事では、強化学習の組合せ最適化問題への適用について紹介しました。まだまだ発展途上の技術ではありますが、学術界・産業界の両方において、アルゴリズム開発や実問題への実証実験が精力的に進められており、今後その応用事例が増えることが期待されます。
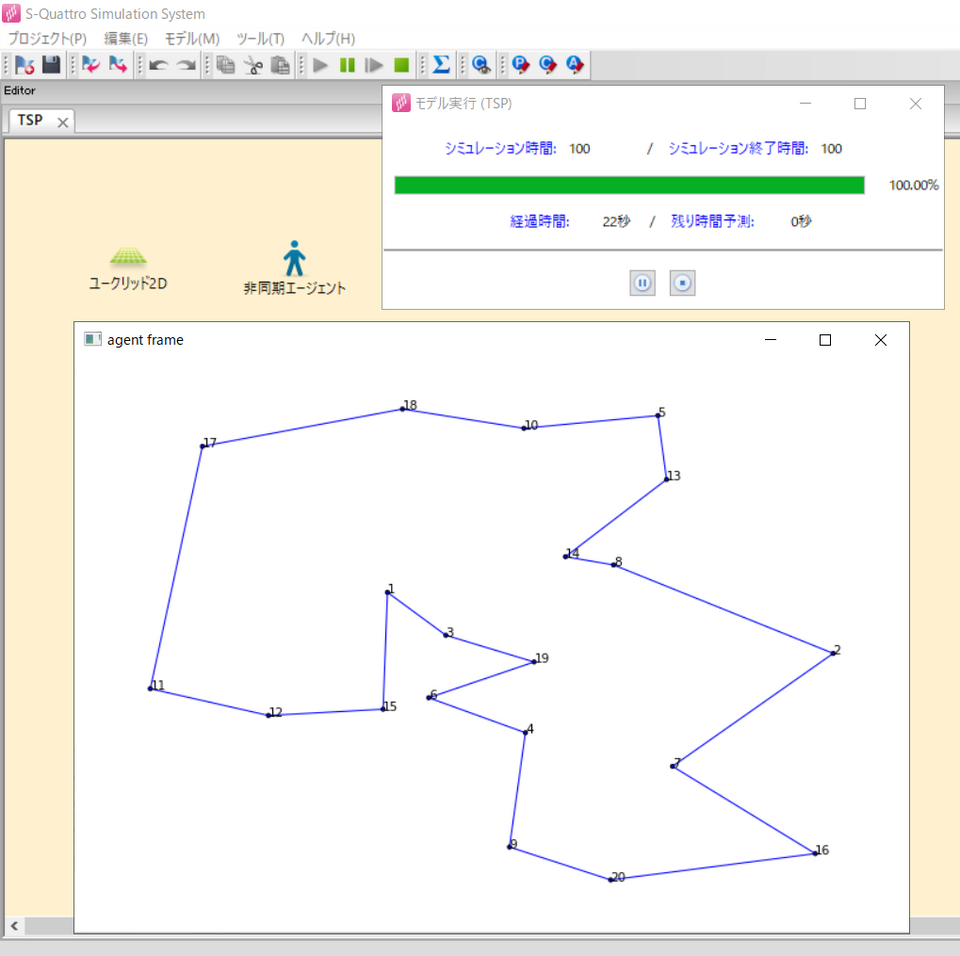
次回は深層強化学習を用いて巡回セールスマン問題を実際に解いてみた結果について紹介予定です(図2)。
参考文献
- Mazyavkina, Nina, et al. "Reinforcement learning for combinatorial optimization: A survey." Computers & Operations Research 134 (2021): 105400.
- Ma, Qiang, et al. "Combinatorial optimization by graph pointer networks and hierarchical reinforcement learning." arXiv preprint arXiv:1911.04936 (2019).
- Joshi, Chaitanya K., et al. "Learning TSP requires rethinking generalization." 27th International Conference on Principles and Practice of Constraint Programming (CP 2021). Schloss Dagstuhl-Leibniz-Zentrum für Informatik, 2021.











