- HOME
- 機械学習とは?AI・機械学習でできることやメリット、ビジネス活用のためのポイント

更新日:2025年4月30日 18:05
公開日:2020年6月 7日 19:08
機械学習とは
機械学習とは、与えられた情報から自動的にパターンを抽出(学習)して特定の処理を効率的に実行するプログラムを作成するための技術、研究分野です。 典型的には、情報として人間には確認できないほど大量のデータを与えて、その中からパターンを学習させます。
歴史的には人口知能(AI)の一分野として、コンピューターに人間と似たような形で "パターンを学習" させることができないだろうかという点を主眼に発展してきました。 一方で昨今では、"特定の処理を効率的に実行するプログラムを作成する" という部分が注目され、ビジネスの世界でも積極的に活用されるようになってきました。
与える情報や学習のための手法を適切に設定することで、様々な処理を実行するプログラムを作成することができます。
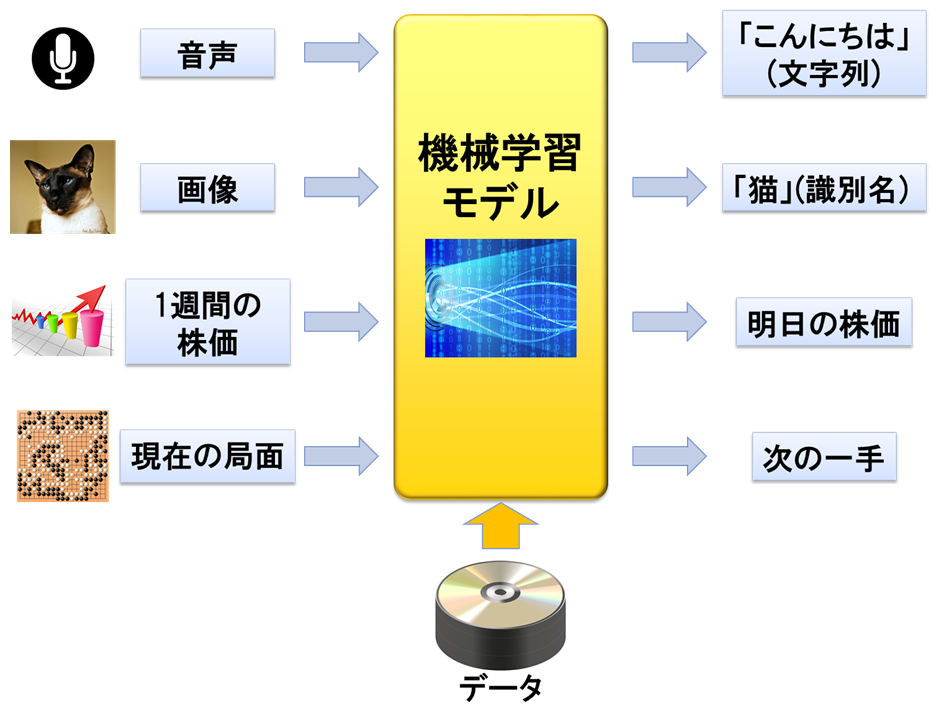
機械学習でできること
機械学習の中の枠組みとしてよく次の3つが挙げられます。
- 教師あり学習
- 教師なし学習
- 強化学習
ただし機械学習の中のアルゴリズムや研究テーマが上記の3つに分類可能なわけではなく、複数にまたがるもの、いずれにも分類できないものも多くあります。
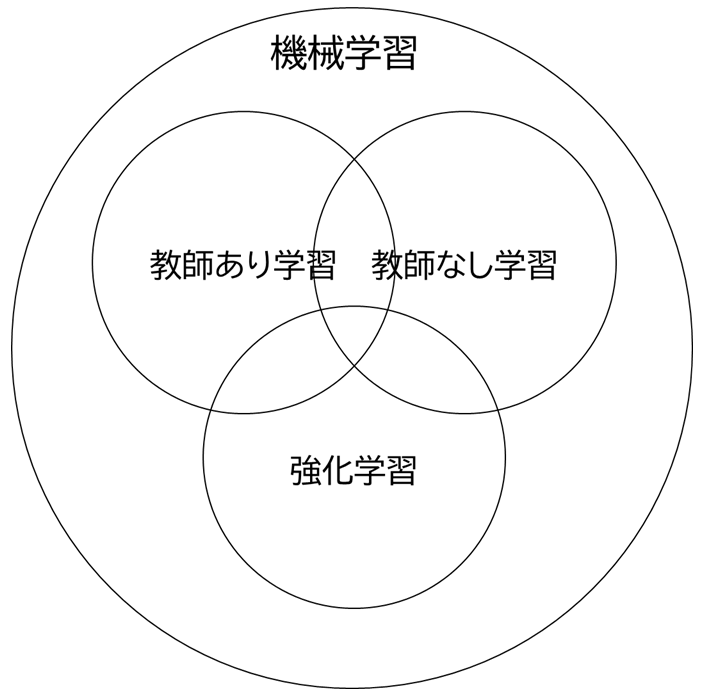
網羅的というわけではなく、あくまで主要な3つの枠組みというだけですが、機械学習でできることを考えるためには分かりやすい分類の仕方なので、これに沿って例を挙げてみましょう。
教師あり学習
教師あり学習では、データと正解の組を学習データとして与え、データだけを与えたときに正解を高精度で予測するプログラムを作成することを目指します。 多くの人がイメージする機械学習はこれではないかと思います。 Neural Network(ディープラーニングを含む)、Gradient Boosting Machine(GBM)、Random Forest(RF)、Support Vector Machine(SVM)など多くの有名なアルゴリズムがこの問題のために考えられてきました。
予測するプログラムは、正解がカテゴリとして与えられる場合は判別モデルもしくは分類モデル、数値として与えられる場合は回帰モデルと呼ばれることもあります。 一般的には回帰モデルの方が判別モデルよりも精度を高くするのが難しいため、予測対象が実際には数値でも正解は「高」「中」「低」のようなカテゴリに変換して判別モデルとして対応する場合もあります。
具体的な応用としては次のようなものが挙げられます。
画像認識による製品の不良品の判別
製品画像とその製品が良品か不良品かの判定結果(正解)のデータを大量に学習させることで、製品画像を与えたらその製品が良品か不良品か判定するプログラムを作成することができます。
画像認識に関しては2012年頃からのディープラーニングの技術の進展が目覚ましく、手法の選択肢としてはディープラーニング(特にCNN系)一択になりそうです。
参考記事
NTTデータ様:画像認識・分類技術による製品管理・分類業務の自動化事例
小売店の仕入れ量の決定のための需要予測
過去数年分の売上データなどを学習させることで、今後の売上高(= 需要量)を予測するプログラムを作成することができます。 人間の購買行動は暦(季節、曜日、祝日)とイベント(年末年始、GW、バレンタイン、お祭り、……)に強く依存するので、これらの情報を適切に学習データとして与えることができれば精度の高い需要予測プログラムを作成することができます。
普通の表形式データに対する予測と考えて GBM などを適用する場合もありますし、時系列性・季節性を学習させることを意識してARIMAモデルや状態空間モデルを適用する場合もあります。
教師なし学習
教師なし学習では、正解のないデータを学習データとして与え、データの中に存在するパターンを抽出することを目指します。 機械学習で扱うデータは数万件以上のオーダーになることも普通ですので、教師あり学習では正解を付けることが難しいという課題がありますが、教師なし学習では正解なしでも学習できるという点が強みになります。 ただし、教師あり学習よりも目標が抽象的であいまい(非明示的)なので、できるプログラムを現実の問題にどう活用するのかをきちんと設計しておかないと、「おもしろいことはできるけど、これからどうしようか?」という状態になってしまいがちです。 特に、教師あり学習の場合の「予測精度」のようなプログラムの良し悪しを評価する指標がない場合が多いので、どのように定量的な評価を与えるのかを検討しておくことは重要です。
具体的な応用としては次のようなものが挙げられます。
設備の異常検出(外れ値検出)
設備のセンサーデータから正常/異常の判定を行いたいという課題がよくあります。 正常/異常を正解ラベルとして与えることで教師あり学習の枠組みで判別モデル作成の問題として処理することができそうに見えます。 しかし、判別モデルを作成するためにはどの正解ラベルに対しても十分多くのデータが与えられることが求められます。 一般的に設備の異常というのは1年に1度発生するかどうかというレアなイベントであることが多いので、機械学習でパターンが学習できるほど「異常」のデータを与えることができません。
この場合、教師なし学習の枠組みの中の外れ値検出(anomaly detection)という分野の手法が活用できます。 与えられたデータはほぼ正常データだと考え、正常データの特徴を学習し、そうでないものを外れ値として検出します。 あくまで外れ値であって、それが異常であるかどうかを判定するものではありませんが、アラートを出して異常「疑い例」をスクリーニングするというような使い方ができます。
One-Class Support Vector Machine(OCSVM)、Local Outlier Factor(LOF)、Isolation Forest(iForest)など様々な外れ値検出アルゴリズムがあり、それぞれ外れ値として検出するものが違います。 複数のアルゴリズムを試してやりたいことにマッチするのはどのアルゴリズムなのかを調べるという進め方になる場合が多いと思います。
異常データがほぼ存在しないというのは、出来上がったプログラムを評価する際にも大きな課題になります。 過去に数件でも異常が発生しているのであれば、まずはそのケースを外れ値として検出できるかどうかを評価しましょう。 異常ケース数件ではプログラムの信頼性に確証が持てない、異常ケースはそもそもデータとして存在しないという場合には、ヒヤリハットの記録、メンテナンス記録(定期メンテナンスでなければ何らかの問題を発見した可能性がある)などと突き合わせて、その前後の時間帯でモデルが高い「異常度」を出していないかなどを評価指標として考える場合が多いです。
画像生成
教師なし学習の枠組みの中に生成モデルという分野があります。 与えられたデータの特徴を学習し、そのデータと似ている偽物のデータを出力するプログラムを作成するものです。 特に近年は Generative Adversarial Networks(GAN)とその派生手法で画像生成が非常に高精度に実現できるようになりました。
上記の手法の実用的な応用に、画像の高精細化、モノクロ写真や線画の着色、「画風」に沿った画像改変があります。
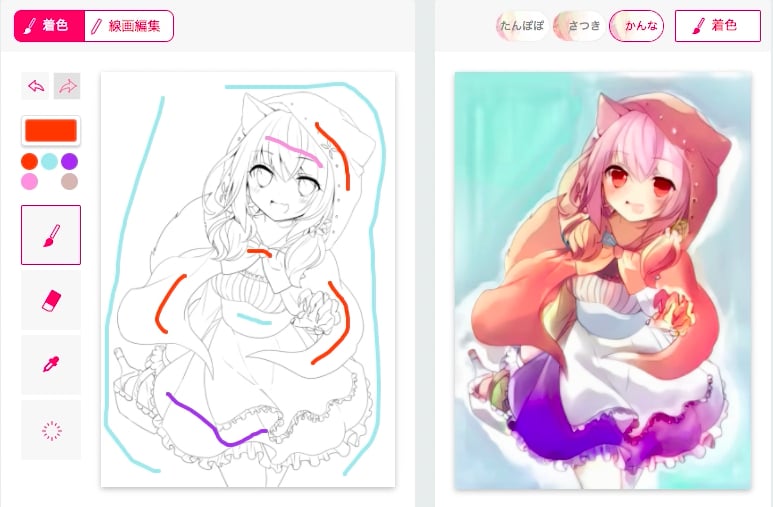
ピクシブ株式会社の提供する線画自動着色サービス「Petalica Paint」の着色例。
左の線画と大まかな色指定から、右の着色済みの画像を生成できます。
画像生成で難しいのは評価です。定量的な指標はいくつか検討されていますがあくまでモデルとしての数値的な評価で、実用的に使える画像が生成されているのかとは少し違うものになりそうです。 最終的には人間がその精度で使えると判断できるかどうかが問題になりそうですので、完全に定量的に評価するというのは難しく、「だいたいうまくいってるんじゃない?」というあいまいな評価が最終的な結論になってしまいそうです。 このような評価が難しいケースの場合、必ず人間が補正する下書きとして扱う、まずは技術のケイパビリティ―を見るものとして業務とは離れたところで使うというような運用面でのカバーが必要になります。
強化学習
強化学習は、「状況判断してアクションを起こし、そのアクションに対する報酬を得る」という処理を繰り返したときに、最終的な報酬を最大化するための戦術を学習するための枠組みです。 報酬という概念が教師あり学習の正解に似ていますが、それぞれの状況に単純な正解があるわけではなく、一時的には損をするが長期的に報酬が大きくなるという可能性も考慮した上で最適なアクションを選択できるようになることを目指すという点がポイントです。
ディープラーニング(深層学習)と強化学習を組み合わせた深層強化学習という分野が最近は非常に注目を浴びています。 コンピューターはもうしばらく人間に勝てないだろうと言われていた囲碁の世界で、DeepMind社の開発した AlphaGo という囲碁プログラムがトッププロに連勝したことで大きな話題となりました。 自動運転技術の主要な技術として深層強化学習が使われていることも有名です。
非常に多くの選択肢から最適な選択を得られるようにするためには、様々な状況で大量の試行錯誤を行うことが必要になります。 強化学習の枠組みとしてシミュレータが絶対に必要というわけではありませんが、過去に得られている観測データから学習させる方法(方策オフ学習)では状況の網羅性が足りず、かといって、実環境とエージェントを相互作用させる学習(方策オン学習)では処理時間がかかるため大量の試行錯誤ができません。 このため現実を模したシミュレータを作成してその中で学習を行わせるのが典型的な方法です。
ボードゲームやビデオゲームであればシミュレータを作成するのは比較的容易ですが、現実の問題で適切なシミュレータを作成するというのは難しいタスクです。 深層強化学習を適用するためにシミュレーターを作れるのかというのは大きな壁ですが、物理方程式に従って環境が変化するというような問題設定は比較的シミュレータの作りやすいもので、例えば下記の事例のように建物の振動制御の方法を学習させることができます。
株式会社NTTファシリティーズ様:長周期地震動による超高層建物の揺れを深層強化学習AIで制御
参考記事
当社の社員が強化学習の紹介をした記事です。
機械学習とシミュレーションの融合
その他の枠組み
上記に挙げたのは機械学習の代表的な枠組みというだけで、他にも様々な枠組みが考えられています。 ビジネス的には、「教師あり学習がやりたいけれど正解付きデータはそんなに大量に準備できない」というのがよくある課題ですが、例えばそのような課題に対処する枠組みとして次のようなものがあります。
半教師あり学習は、大量の正解なしデータと少量の正解付きデータを学習させて、高精度の予測を行うこと目指すための枠組みです。 教師なし学習のように正解なしデータからデータの特徴抽出の仕方を学び、教師あり学習のように正解付きデータから対象の予測の仕方を学ぶという、いいとこどりのようなイメージの考え方です。
メタラーニングという、事前に対象データではない大量の学習データで学習方法自体を学習しておくことで、本番の学習は少量のデータでも効果的に学習できるようにするという枠組みの研究もあります。 特に画像認識の分野で、数枚のデータ、場合によっては1枚のデータでも精度の良い予測モデルが作成できる場合があるということで、Few-Shot、One-Shot というキーワードで近年注目されています。
参考記事
当社の社員が Ladder Network の紹介をした記事です。
Deep Learning は半教師あり学習で簡単になる

ビジネスで機械学習を使うために考えるべきこと
機械学習を使うべき?
最近は機械学習というキーワードがポピュラーになってきましたので、「こういうことしたいんだけど、機械学習でできるんでしょ?」というご相談を受けることも非常に多いです。 しかし、機械学習は魔法ではなく現実の技術の一つにすぎませんので、得意なこと、苦手なことがあり、特性を見極めて使うかどうかを判断するべきです。
100%ではないことが許されるか
機械学習による予測プログラムは、学習データに習うと統計的に高い確率でそうなるということを予測するものですので、100%当たることは保証できません。
また、精度に対する要請も様々です。 例えば「99%の正解率で予測できます」と言われるとすごそうに感じますが、これが使い物になるかはプログラムの結果が引き起す事態に対する緊張感と、いざ不具合が起きた場合に人間も含めたシステムでどれだけサポートできるかどうかにかかっています。 ECサイトで「あなたへのお勧め」を表示するためのプログラムであれば、1%の確率で全く興味のない商品を表示しても気にする人は少ないでしょう。 がん検診で1%の確率でがんを見逃してしまうと言われると、このシステムで診断されるのはちょっと嫌だなと思う人も多いのではないかと思います。 同じく、がん検診で1%の確率でがんを見逃してしまう状況でも、「あくまで予備診断であって、陰性の場合でも人間のお医者さんがもう一度確認する仕組みです」と言われたら、そういうものだなと思ったり、むしろ人間だけで診断するより高精度に検出できて良いことだと思う人も多いでしょう。
機械学習がプログラムであるという考え方をしてしまうと、間違いの起こらないプログラムにしたいという発想になりがちです。 どちらかというと人間の代替であって、高い精度で賢く処理できるけれどたまにはヒューマンエラーが発生するのは避けられないので、たまにエラーが発生するという前提でシステム全体としてカバーできる仕組みを考えようという考え方が必要です。 これが許容できないのであれば、そもそも求めているものは機械学習ではなく、決められた処理を間違いなく実行する普通のプログラムなのかもしれません。
データは十分に使えるか
機械学習で高精度な予測を実現するためには、多くの場合で前提として十分な学習データを用意できるのであればという条件が付きます。 必要なデータ量は問題設定にも依存しますので一概には言えませんが、典型的には数万件オーダーの学習データとして準備できることが求められます。
上で述べた Few-Shot のように正しい予測をするのに必要なデータをできるだけ削減する、というような方法論やアルゴリズムは提案されていますが、現在まだまだ発展途上で研究的な取り組みとなってしまわざるを得ません。 研究開発なのでうまくいかなくても良く、自分の手元のデータを使ってどの程度の精度が出せるのか試してみたいというような問題設定であれば喜んでご支援させていただきますが、すぐに実用的な成果を出したいという問題設定だとお勧めしかねます。
機械学習でデータが大量に必要なのは学習をさせるためですので、大量なデータが得られない場合には学習済みのモデルを用いる方法もあります。 実際に人間の顔画像の認識、特定分野の画像の認識、テキストの処理など典型的なタスクに対しては既に学習済みのモデルを使用したプログラムがサービスとして提供されている場合もよくあります。 問題設定が同じであれば、自分でデータを蓄積してモデルを作成するよりも、既存のサービスを使用する方が低コストで高精度になる場合が多いので、そのようなサービスが使えないかを検討してみましょう。
一般的な問題設定ではないので自分のデータを使用する必要があるがデータが十分でないという場合は、統計解析的なアプローチを視野に入れて考えると良いと思います。 統計解析では少量のサンプルからデータに関する知見を得るというのは伝統的なテーマですので、数十件、数百件のデータに対してもできることは少なからずあります。
機械学習より適した方法がないか
ビジネスで機械学習関連の技術を調べている皆さんのやりたいことは機械学習の研究ではなく、抱えているビジネス課題の解決のはずです。 できるだけ効率的に課題を解決するためには、似たような問題を解決している事例が存在しないかどうかを調べてみることがまず重要です。
データから知見を得たり、データを活用して効率的に処理を行うアルゴリズムを作成することを目指す研究分野としては、次のようなものがあります。
- 機械学習
- 統計解析
- 数理計画・最適化
- データマイニング
- シミュレーション
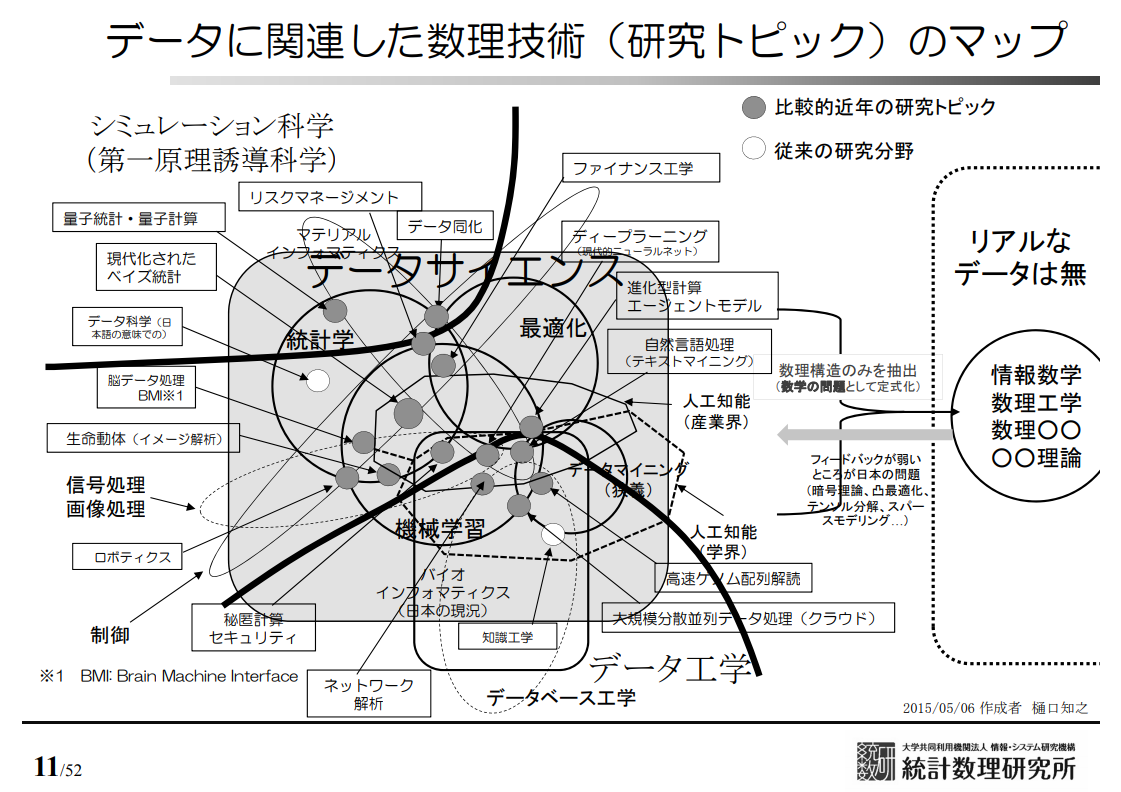
統計数理研究所所長(当時)の樋口先生による研究トピックマップ。機械学習の周辺に様々な関連する研究分野、重複する研究分野があることが分かります。
それぞれの研究分野に共通部分もあり、どの手法はどの分野だと簡単に説明することは難しいのですが、多くの研究分野でデータを活用して何かを実現するというのが現在の非常に重要なテーマになっているのは間違いありません。 「AI・機械学習で解決したい」と視野を狭めて探し始めると、「実はこの問題は別の分野では典型的な手法で解決できた」ということを見逃してしまうことになりかねせん。
統計解析に関する記事はこちら
数理計画・最適化に関する記事はこちら
シミュレーションに関する記事はこちら
おわりに
具体的なビジネス課題がある場合、それが定番化した技術で解決できる取り組みやすい課題なのか、技術検証から始めるようなチャレンジングな課題なのかをまず見極め、どの程度のコスト・時間まで許容できるかという判断をしていくことになると思います。 機械学習やその周辺の研究分野は近年発展が目覚ましく、常に情報が更新されていきます。 当社のようにデータ分析を専業でやっていれば、最近の技術動向をキャッチアップして、課題に対してどの程度の難易度なのか、検証するべきポイントは何かという見極めはできますが、本業が他にある方においては、技術動向を把握するというのはなかなか難しいのではないかと思います。
このようなことでお悩みの方がいらっしゃいましたら、ぜひ当社にご相談ください。 「こんなデータがあるけど何かできない?」というざっくりしたご相談ですとお答えしにくいですが(それでも可能な限りお答えします!)、「こんなオペレーションがあって、この部分を効率化したい。データは既にこんなものがある。」というような具体的なご相談をいただければ営業対応の範囲で下記のような情報はご提供できるかと思います。
- ○○という分野の○○という技術が使えるのではないか
- 定番の技術があってすぐに解決できそうな課題なのか、難しい課題なのか
そこからさらに、「具体的なテーマに絞って技術調査・論文サーベイが必要」、「不確定要素が強いので PoC(Proof of Concept、実証実験)をするべき」といった技術目線のご提案や、システム化に向けてのマイルストーンのご提案も可能です。
また、「自社で技術を身に付けていきたい」というケースもあるかと思います。 当社では、AI・データ分析を内製化できるデータ分析プラットフォーム Alkano の開発・販売も行っています。また、データサイエンス教育なども実施しています。
上記以外でも、データ分析に関わることであれば何でもご相談に応じますので、お気軽にお問い合わせください。











