- HOME
- Nuorium Optimizer V28 シンセシスソルバーをご紹介! 分枝限定法とメタヒューリスティクスの融合による高速化
![]()
更新日:2026年5月12日 16:17
公開日:2026年4月21日 13:00
NTTデータ数理システムです。2026 年 3 月 に Nuorium Optimizer V28 をリリースしました。 本記事では V28 の新機能であるシンセシスソルバーをご紹介します。 なお、本記事に登場する重み付き局所探索法 wls については次の記事をご覧ください。
- Nuorium Optimizer V27 新機能のご紹介! 重み付き局所探索法の並列計算
- Nuorium Optimizer V26 新機能を活用!重み付き局所探索法を用いた 2D Strip Packing Problem の求解
混合整数線形計画問題(MILP)の解法
混合整数線形計画問題(MILP)の解法として有名なのは単体法ベースの分枝限定法です。 ここで、単体法とは線形計画問題(LP)の解法であり、MILP における整数性を緩和した問題(LP緩和問題)を単体法によって解くことで目的関数の下界値を得ることができます。 この「LP緩和問題を単体法によって解いて下界値を得る」という操作を軸に、探索領域を分割・限定しながら最適解を探すのが分枝限定法です。 詳細は弊社の分枝限定法の解説ページをご覧ください。
一方で、分枝限定法は最適解を得る手法ですが、実務上は最適であることよりも短時間に良質な解を得ることの方が重要な場面もあります。 このような状況にマッチする手法としてメタヒューリスティクスに代表される近似解法があり、Nuorium Optimizer に搭載されている重み付き局所探索法 wls もその一つです。 どちらの解法にも強み・弱みがあるため状況に応じて適切な解法を選ぶ、というのが最適化を使う側の責任でした。 シンセシスソルバーはこれを大胆な発想で解決する新しい解法です。
シンセシスソルバー
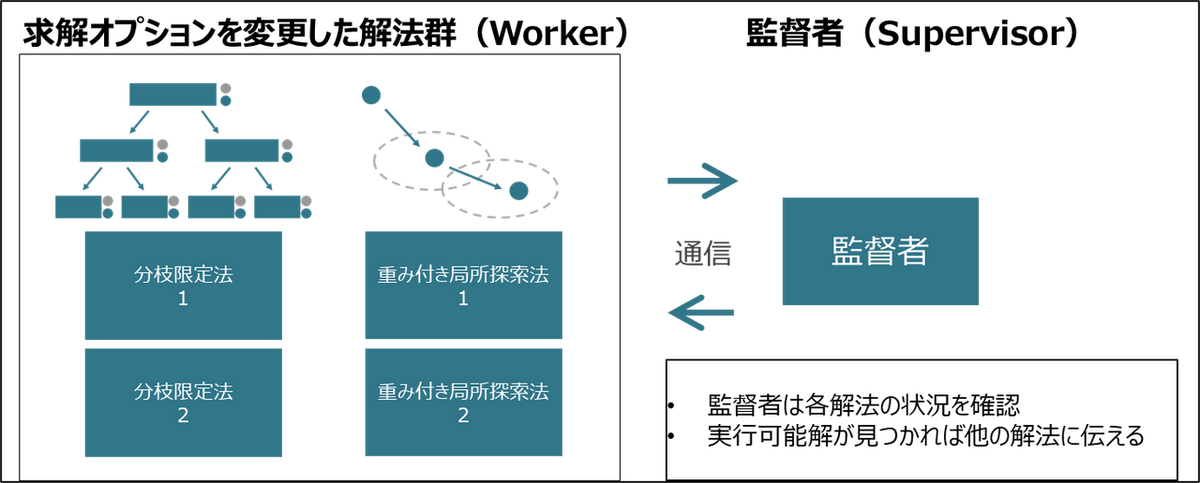
シンセシスソルバーの発想は非常に単純で、両方の解法を同時に実行するというものです。 ただ、これだけだと両方の解法を別プロセスで走らせるだけになり、両者のシナジーが生まれません。 そこで、Nuorium Optimizer の分枝限定法の並列計算である Racing [1] のフレームワークに重み付き局所探索法 wls を追加します。
Racing は内部で複数の Worker が並列に解を探索し、Supervisor がそれを統括する仕組みです。アルゴリズムのパラメータを変更した Worker をスレッド数分用意することで探索に多様性を持たせ、さらに Supervisor を介して Worker の状況や実行可能解を共有するため、探索を並行させる以上のシナジーを期待することができます。
今回は分枝限定法と wls を Racing のフレームワークに載せることで次のような効果を期待できます。
- 分枝限定法の強み:最適解を得ることができる。最適解が得られなくても下界値を取得できる
- wls の強み:高速に良質な実行可能解を得る
- 分枝限定法と wls のシナジー:それぞれの解法で得られた実行可能解をもう一方の解法に共有することで、探索領域の限定や良質な実行可能解の発見が期待できる
シナジーの具体的な説明については技術的な内容を含むため詳細は省略しますが、両者の強みを生かしつつシナジーが得られることが伝わるかと思います。本記事の後半では実際の問題を例に挙げてその性能を確認していきます。
無関連並列機械スケジューリング
シンセシスソルバーの性能を確認するために、ここでは無関連並列機械スケジューリングを取り上げます。 並列機械スケジューリングとは全てのジョブをいずれかの機械に割り当てる問題です。工程は一つのみです。 「無関連」とは機械 i がジョブ j を処理する時間 p[i, j] について、具体的に p[i, j] を求める式(法則性)が存在しないという意味を持っています。 逆に法則性がある設定として次のようなものがあります。
- 同一並列機械スケジューリング:機械 i が全て同じ性能で、p[i, j] がジョブ j のみに依存
- 均一並列機械スケジューリング:機械 i の性能は異なるが一貫した法則がある(例えば p[i, j] がジョブ j の量 s[j] と機械 i の性能 p[i] で決まり、p[i, j] = s[j] / p[i] と表せる)
無関連並列機械スケジューリングはかなり一般的な設定であり、例えばボトルネックとなる工程を取り出してスケジューリングを最適化する際に登場します。

続いて、無関連並列機械スケジューリングの定式化は文献 [2] を参考に次のようになります。定式化の説明は省略します。

計算実験
まずはインスタンス(最適化問題を定義するデータ)を生成します。生成したインスタンスの名前を A_B_C_D とします。
ここで A, B, C, D は次の通りです。
- A:ジョブの数
- B:機械の数
- C:段取り替えの下限値
- D:段取り替えの上限値
段取り替えは下限値と上限値を元に一様分布で整数値を生成します。また、処理時間は [1, 99] の範囲で一様分布で整数値を生成します。 最適化問題は Nuorium Optimizer の PySIMPLE で記述します(後述)。 計算時の設定はスレッド数 4、計算時間上限 1,800 秒、メモリ上限 16 GB、CPU 性能は Intel Core i5-13600K、RAM 性能は 32 GB 4800MT/秒 です。 計算結果は次の通りです。ここで bb は分枝限定法、wls は重み付き局所探索法、synthesis はシンセシスソルバーを意味します。
| インスタンス | bb | wls | synthesis |
|---|---|---|---|
| 100_10_1_124 | 1,011 | 563 | 286 |
| 100_10_1_99 | - | 314 | 193 |
| 100_10_1_49 | 224 | 136 | 318 |
| 100_10_1_9 | 276 | 417 | 250 |
| 100_5_1_124 | 694 | 1,767 | 574 |
| 100_5_1_99 | 650 | 993 | 464 |
| 100_5_1_49 | 317 | 500 | 331 |
| 100_5_1_9 | 952 | 1,591 | 548 |
| 50_10_1_124 | 526 | 146 | 133 |
| 50_10_1_99 | 116 | 110 | 97 |
| 50_10_1_49 | 56 | 57 | 56 |
| 50_10_1_9 | 555 | 146 | 106 |
| インスタンス | bb | wls | synthesis |
|---|---|---|---|
| 100_10_1_124 | 722 | 124 | 13 |
| 100_10_1_99 | - | 48 | 18 |
| 100_10_1_49 | 1,493 | 104 | 12 |
| 100_10_1_9 | 526 | 344 | 23 |
| 100_5_1_124 | 222 | 292 | 10 |
| 100_5_1_99 | 286 | 220 | 22 |
| 100_5_1_49 | 93 | 152 | 6 |
| 100_5_1_9 | 179 | 428 | 27 |
| 50_10_1_124 | 14 | 4 | 2 |
| 50_10_1_99 | 48 | 4 | 2 |
| 50_10_1_49 | 15 | 4 | 6 |
| 50_10_1_9 | 34 | 4 | 2 |
考察
今回の計算結果から、シンセシスソルバーは分枝限定法(bb)と重み付き局所探索法(wls)の双方の長所を引き出し、協調動作によって各手法を上回る性能を示しました。
まず、実行可能解(初期解)の発見が他の手法に比べて高速です。分枝限定法と比較すると顕著に差が出ていることが確認できます。 一方で wls とも大きな差があります。これは Nuorium Optimizer の仕組み上、通常の wls では適用されない前処理(スケーリングや LP 用の軽量な処理)がシンセシスソルバーで施されることにより、 シンセシスソルバーの wls がより高速化したと考えられます。これは wls 自体の高速化として LP や MIP の前処理が効果的であることを示唆しています。
また、シンセシスソルバーによる最終的な目的関数値も他の手法に比べて高品質です。 特に大規模インスタンスでは差が顕著で、両者の強みが合わさることで安定的に高品質な解へ到達しています。
以上より、シンセシスソルバーが有効であることが確認できました。
参考:無関連並列機械スケジューリングの PySIMPLE モデル
from pysimple import *
class Data():
def __init__(self, N, M, sijk, pij, instance_name):
self.N = N # ジョブのリスト
self.M = M # 機械のリスト
self.sijk = sijk # 段取り替え時間
self.pij = pij # 処理時間
self.instance_name = instance_name
def model_MILP(data):
dummy_job = 0
i = Element(value=data.M) # 機械
j = Element(value=data.N) # ジョブ
k = Element(value=data.N) # ジョブ
j0 = Element(value=[dummy_job] + data.N) # ジョブ
k0 = Element(value=[dummy_job] + data.N) # ジョブ
h0 = Element(value=[dummy_job] + data.N) # ジョブ
sijk = Parameter(index=(i, j0, k0), value=data.sijk) # 段取り替え時間、dummy_job を含む
pij = Parameter(index=(i, j0), value=data.pij) # 処理時間、dummy_job を含む
ij0k0 = Condition((i, j0, k0), j0 != k0)
X = BinaryVariable(name='X', index=ij0k0) # ジョブ j がジョブ k よりも先行する
C = Variable(name='C', index=j0, lb=0) # ジョブ j の作業完了時刻
Cmax = Variable(name='Cmax', lb=0) # 機械 i の作業完了時刻
p = Problem(name=data.instance_name)
p += Cmax, 'min. objective' # メイクスパンの最小化
ij0k = Condition((i, j0, k), j0 != k)
p += Sum(X[ij0k], ij0k(0, 1)) == 1, '(2)[k]' # ジョブ k はジョブ j0 よりも後ろになる
ijk0 = Condition((i, j, k0), j != k0)
p += Sum(X[ijk0], ijk0(0, 2)) == 1, '(3)[j]' # ジョブ j はジョブ k0 よりも前になる
for _j, in j.set:
for _i, in i.set:
_k0 = k0 != _j
_h0 = h0 != _j
p += Sum(X[_i,_j,_k0], _k0) == Sum(X[_i,_h0,_j], _h0), f'flow_{_j}_{_i}'
p += Sum(X[i, dummy_job, k], k) <= 1, '(5)[i]'
V = Sum(pij[i, j]) + Sum(sijk[i, j, k]) # big-M
p += C[ij0k(2)] - C[ij0k(1)] + V*(1-X[ij0k]) >= sijk[ij0k] + pij[ij0k(0,2)], '(6)[i,j0,k]'
p += C[dummy_job] == 0, '(7)'
p += C[j] <= Cmax, '(8)[j]'
p += Sum((sijk[ij0k] + pij[ij0k(0,2)]) * X[ij0k], ij0k(1,2)) <= Cmax, '(13)[i]'
return p, X, C
参考文献
- Y. Shinano, et al., Solving open MIP instances with ParaSCIP on supercomputers using up to 80,000 cores. In: Parallel and Distributed Processing Symposium, 2016 IEEE International. IEEE. 2016, pp. 770-779.
- O. Avalos-Rosales, F. Angel-Bello and A. Alvarez, Efficient metaheuristic algorithm and re-formulations for the unrelated parallel machine scheduling problem with sequence and machine-dependent setup times. Int. J. Adv. Manuf. Technol. Springer. 2015, pp. 1705–1718.











