- HOME
- psim言語講座(第3回)待ち行列 M/M/1 シミュレーションを拡張してみる

更新日:2025年2月12日 18:14
公開日:2021年8月24日 17:45
本記事は当社が発行しているシミュレーションメールマガジンVol.3の記事です。
シミュレーションメールマガジンの詳細・購読申込はこちら
のサポートページから
M/M/1 モデル
前回、M/M/1 モデルを psim で構築し、実行してみました。[プログラムはこちらからダウンロード]
M/M/1 モデルとは、同時に 1 つのみ行えるサービスに対し、ランダムに利用者が到着し、ランダムな時間サービスを利用するようなモデルの事でした。
今回は、そのコードの中身を詳しく読んで行こうと思います。
区役所モデル
M/M/1 モデルを拡張すれば、様々なシミュレーションを構築出来ます。
今回は、もう少し現実的な区役所モデルを作ってみます。
簡略化した区役所では、住民票、戸籍、印鑑証明が取得出来ます。
利用者は平均 60 秒で到着するとしますが、各利用者は以下の割り合いで サービスを利用します。
| サービス | 割り合い |
|---|---|
| 住民票 | 0.6 |
| 戸籍 | 0.1 |
| 印鑑証明 | 0.3 |
サービスごとに、処理時間は異なり、書類発行には以下の時間を要します。
| サービス | 平均処理時間 |
|---|---|
| 住民票 | 3分 |
| 戸籍 | 4分 |
| 印鑑証明 | 2分 |
この時、平均待ち時間を 10 分以内になるように複数の窓口を準備しよう としています。窓口をどのぐらい用意すれば良いかシミュレーションして調べてみます。
では、具体的に区役所モデルのコードを見て行きたいと思います。
サービスの分布
サービスの分布は、psim の empiricalDistribution を使って表現できます。
具体的には以下のようにしてサービス種別を返す乱数生成器を作成しています。
r = [0.6, 0.1, 0.3] # 住民票、戸籍、印鑑証明の割合
...
# サービス種別(住民票、戸籍、印鑑証明)を返す乱数発生器
gs = empiricalDistribution([(v, i) for i, v in enumerate(r)])
empiricalDistribution の引数はリストで、各要素は重みと値のタプルです。
この時、next(gs) は、指定された重みで、0(住民票), 1(戸籍), 2(印鑑 証明) を返します。
サービス時間の分布
サービス時間は、サービス毎に異なります。そのため、 exponentialDistribution のリストとして表現します。
具体的には以下のようにしてサービス時間を返す乱数生成器のリストを作成しています。
m = [3 * 60, 4 * 60, 2 * 60] # 住民票、戸籍、印鑑証明のサービス時間
...
# 各サービス時間を生成する乱数発生器
gt = [exponentialDistribution(m0) for m0 in m]
この時、next(gt[s]) は、サービス s の処理時間を返します。
資源の定義
今回、窓口の数 ns は、可変とします。
そのため、ファシリティの定義を変更しています。
# 窓口を示すファシリティ資源
f = Facility(ns, monitor = True)
到着プロセス
到着プロセスは M/M/1 モデルとほぼ同じです。
# 到着プロセス
def arrive():
while True:
# 次の到着まで待つ
yield pause(next(g1))
# サービス種別を決定
s = next(gs)
# サービスプロセスを開始する
# - この処理自体は非同期なので、一瞬で完了する
yield subactivate(service)(s)
到着後に、サービス種別 s を決定し、サービスプロセスに s を伝えています。
サービスプロセス
サービスプロセスも M/M/1 モデルとほぼ同じです。
def service(s):
t0 = now()
# 窓口の待ち行列に並ぶ
# - 窓口を示すファシリティ資源の利用を予約する
# - 既に利用者がいる場合は、利用可能になるまで待ち受ける
lock = (yield f.request(name = "lock"))["lock"]
# 窓口サービスを開始する
# - 窓口を示すファシリティ資源の利用権を取得した
# - 利用権を開放するまで他の利用者は利用できない
t1 = now()
# 待ち時間を記録
monitor.observe(t1 - t0)
# 窓口を利用する
yield pause(next(gt[s]))
# 窓口を示すファシリティ資源の利用権を開放する
lock.release()
サービスプロセスを起動する時に、どのようなサービスなのかが引数 s に渡ってきます。
窓口の利用時間はサービス毎に違います。サービス s に対応したサービス時間は、next(gt[s]) として求まります。
結果をまとめる
まず、sim 関数は、窓口数 ns を受け取り、待ち時間とシステム内客数のタ プルを返す関数にしています。
以下のように、シミュレーションを回し、結果を pandas のデータフレーム 化しています。
result = []
for ns in range(1, 5):
waitingTime, queue = sim(ns)
result.append([ns, waitingTime, queue])
df = pd.DataFrame(result, columns = ["窓口数", "待ち時間", "客数"])
print(df)
グラフ作成
以下のようにすると、結果を棒グラフで表示できます。
plt.rcParams['font.sans-serif'].insert(0, "Meiryo")
fig, ax = plt.subplots(1, 2)
ax[0].bar(df["窓口数"], df["待ち時間"])
ax[0].set_ylabel("待ち時間(秒)")
ax[0].set_xlabel("窓口数")
ax[1].bar(df["窓口数"], df["客数"])
ax[1].set_ylabel("客数(人)")
ax[1].set_xlabel("窓口数")
plt.tight_layout()
plt.show()
まとめ
以上で、区役所モデルが作成できました。
区役所モデルは、こちらよりダウンロードできます。
S-Quattro Simulation System がインストールされている PC 上の適当な フォルダに上記 zip を展開下さい。
zip 内には、
- cityoffice.py
- cityoffice.bat
があります。cityoffice.py が区役所モデルを実装したコード例です。cityoffice.bat をそれを実行するための bat ファイルです。
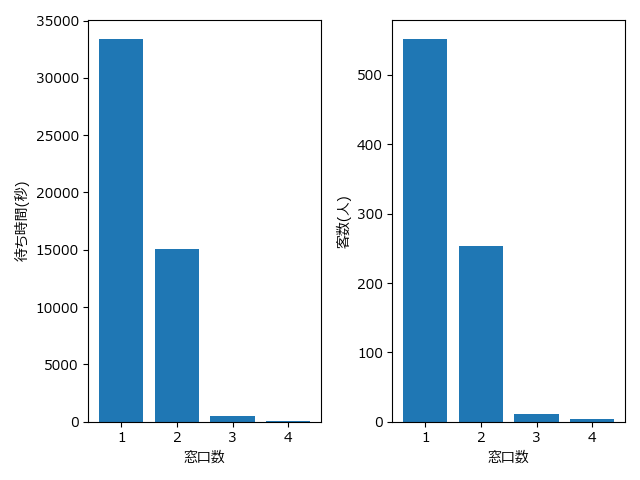
実行結果は以下のようになりました。
| 窓口数 | 待ち時間 | 客数 |
|---|---|---|
| 1 | 33416.37秒 | 552.21人 |
| 2 | 15054.23秒 | 252.65人 |
| 3 | 520.40秒 | 11.66人 |
| 4 | 64.66秒 | 3.84人 |
つまり、平均待ち時間を 10 分以内になるようにするには、窓口を 3 つ用意すれ ば良いという事になります。
このように M/M/1 モデルを拡張していけば、より現実的なシミュレーショ ンを行える事がお分かりになったでしょうか。


- psim言語講座(第1回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を書いてみる
- psim言語講座(第2回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を読んでみる
- psim言語講座(第3回)待ち行列 M/M/1 シミュレーションを拡張してみる
- psim言語講座(第4回)生産ラインシミュレーションを書いてみる
- psim言語講座(第5回)psimとexcelを連携してみる
- psim言語講座(第6回)psimとexcelを連携してみる(グラフ編)
- psim言語講座(第7回)連続型シミュレーションを書いてみる
- psim言語講座(第8回)エージェントシミュレーションを書いてみる
- psim言語講座(第9回)エージェントシミュレーションを拡張してみる
- psim言語講座(第10回)チュートリアル編(1)psim で 「Hello World!」
- psim言語講座(第11回)チュートリアル編(2)psim のプロセスを使いこなす
- psim言語講座(第12回)チュートリアル編(3)psim のファシリティを使いこなす
- psim言語講座(第13回)チュートリアル編(4)psim のストアを使いこなす
- psim言語講座(第14回)チュートリアル編(5)psim のスケジューラを使いこなす
- psim言語講座(第15回)チュートリアル編(6)(続)psim のストアを使いこなす
- psim言語講座(第16回)チュートリアル編(7)(続)psim のストアを使いこなす
- psim言語講座(第17回)チュートリアル編(8) AGV による搬送
- psim言語講座(第18回)チュートリアル編(9) 動的スケジューリング方式
- psim言語講座(第19回)チュートリアル編(10) 強化学習AGV方式






