- HOME
- psim言語講座(第18回)チュートリアル編(9) 動的スケジューリング方式

更新日:2025年8月13日 16:37
公開日:2025年4月15日 17:51
本記事は当社が発行しているシミュレーションメールマガジンVol. 18の記事です。
シミュレーションメールマガジンの詳細・購読申込はこちら
のサポートページから
前回は、AGVによる搬送システムにおいて、納期を基準とした優先度ベース方式のスケジューリングを実装しました。
今回は、さらに高度な「動的スケジューリング方式」を導入し、システム全体の効率化を図ります。また、AGV搬送システムにおけるデッドロックの問題についても検討します。
デッドロックの問題
前回までのモデルでは、工程1と工程2の加工前および加工後の製品置き場の容量を1に制限していました。この容量制限があると、以下のようなデッドロック(システムが進行不能になる状態)が発生する可能性があります:
- 工程1の加工後の製品置き場(t1)が満杯
- 工程2の加工後の製品置き場(t2)が満杯
- AGVが工程1の製品を取得したいが、次の製品を工程2に運ぶ必要がある
- AGVが工程2の製品を取得したいが、次の製品を工程1に運ぶ必要がある
この状況では、どのAGVも先に進めず、システム全体が停止してしまいます。
デッドロック回避の方法
実際の生産システムでは、デッドロックを回避するための様々な方法が採用されています。一般的なアプローチとしては以下のようなものがあります:
予約ベースの方式:
- AGVが製品を搬送する前に、目的地の置き場に空きがあるかを確認し、空きがある場合はその場所を「予約」します。
- 予約が取れた場合のみ搬送を開始し、搬送途中で他のAGVによって目的地が埋まるという事態を防ぎます。
- これは実際の工場で広く採用されている方式で、システム全体を一元管理するコントローラが必要になります。
デッドロック検出と解消:
- システムがデッドロック状態に陥ったことを検出し、特定のAGVを一時的に退避させるなどの解消策を実行します。
- この方法は事後対応型であり、一度システムが停止した後の復旧手段として用いられます。
経路制御:
- AGVが移動できる経路をあらかじめ制限し、循環待ちが発生しないようにします。
- 一方通行のレーンを設けるなど、物理的な制約でデッドロックを回避します。
容量拡大:
- 今回のモデルで採用した方法で、バッファ容量を十分に大きくすることでデッドロックの発生確率を下げます。
- 最も単純な解決策ですが、実際の現場では物理的なスペース制約があるため、無限に容量を増やすことはできません。
今回のモデルでは、実装の簡便さを考慮して容量拡大による方法を採用しました。加工前の製品置き場(s1, s2)および加工後の製品置き場(t1, t2)の容量を無限大に設定します(Storeの容量をFalseに設定することで実現)。
これは実際の生産システムでの実装としては理想的ではありませんが、シミュレーションの目的においては、動的スケジューリングの効果を純粋に評価するために適した選択です。より実践的なシステムでは、予約ベースの方式と動的スケジューリングを組み合わせることで、高い効率性と安定した運用を両立させることができるでしょう。
動的スケジューリング方式
前回の優先度ベース方式では、納期を主な基準として製品の優先順位を決定していました。動的スケジューリング方式では、さらに以下の要素を考慮した製品選択を行います:
- 製品の優先度: 各製品には納期だけでなく優先度(priority)が設定されており、これを意思決定に反映します。
- 納期までの余裕時間: 現在時刻から納期までの時間を考慮します。
- 残り工程数: 製品の残り工程数を考慮して、効率的に処理します。
これらの要素を組み合わせたスコアリング関数を用いて、AGVが取得する製品を決定します。ただし、製品の工程順序(instructions)は厳密に守られます。
スコアリング関数の詳細
動的スケジューリング方式では、製品の優先度スコアを算出するための関数を使用します:
def calculate_priority_score(self, current_time):
if not self.instructions:
return float('inf')
time_to_due = self.due_date - current_time
remaining_processes = len(self.instructions)
estimated_remaining_time = remaining_processes * 10
urgency_factor = 1 / (time_to_due + 1)
priority_factor = self.priority / 5.0
return urgency_factor * priority_factor
この関数は以下の要素を評価します:
- 納期までの余裕時間(time_to_due): 現在時刻から納期までの時間。
- 残り工程数(remaining_processes): 完了までに必要な工程数。
- 緊急度(urgency_factor): 納期が近いほど高い値になる。1/(time_to_due + 1)と計算され、納期までの時間が短いほど値が大きくなる。
- 優先度係数(priority_factor): 設定された優先度(1-5)を5で割った値。優先度が高いほど大きな値になる。
最終的なスコアは、緊急度と優先度係数の積として算出されます。このスコアが高いほど、その製品は優先して処理されるべきと判断されます。
また、各工程の混雑状況を監視するために、ProcessStateクラスを導入しています:
class ProcessState:
def __init__(self):
self.queue_length = 0
self.processing_time = 0
self.last_update = 0
def update(self, current_time):
self.processing_time = current_time - self.last_update
self.last_update = current_time
def get_congestion_score(self):
return self.queue_length * 0.5 + self.processing_time * 0.3
このクラスは各工程のキュー長と処理時間を記録し、混雑状況をスコアとして提供します。これにより、システム全体の状態を監視することができます。
製品選択と工程順序の厳守
動的スケジューリング方式では、製品選択は優先度スコアに基づいて行われますが、工程順序(instructions)は厳密に順番通りに実行されます。これにより、製品の品質とプロセスの整合性を保ちながら、効率的な生産を実現します。
実装コード
動的スケジューリング方式の主要な実装部分を以下に示します:
class Product:
def __init__(self, name, instructions, due_date, priority=1):
self.name = name
self.instructions = instructions
self.due_date = due_date
self.priority = priority
self.start_time = None
self.processing_time = 0
self.completion_time = None
def calculate_priority_score(self, current_time):
if not self.instructions:
return float('inf')
time_to_due = self.due_date - current_time
remaining_processes = len(self.instructions)
estimated_remaining_time = remaining_processes * 10
urgency_factor = 1 / (time_to_due + 1)
priority_factor = self.priority / 5.0
return urgency_factor * priority_factor
class ProcessState:
def __init__(self):
self.queue_length = 0
self.processing_time = 0
self.last_update = 0
def update(self, current_time):
self.processing_time = current_time - self.last_update
self.last_update = current_time
def get_congestion_score(self):
return self.queue_length * 0.5 + self.processing_time * 0.3
process_states = {
T0_LOC: ProcessState(),
T1_LOC: ProcessState(),
T2_LOC: ProcessState(),
T3_LOC: ProcessState()
}
def agv(agvname):
prod = None
current_loc = T0_LOC
while True:
if prod is None:
lock = (yield getlock.request(name="lock"))["lock"]
candidates = []
candidates.extend(t0.buffer)
candidates.extend(t1.buffer)
candidates.extend(t2.buffer)
if candidates:
# 優先度スコアでソートして最も優先度の高い製品を選択
scored_candidates = [(p, p.calculate_priority_score(now())) for p in candidates]
scored_candidates.sort(key=lambda x: x[1], reverse=True)
prod = scored_candidates[0][0]
if prod in t0.buffer:
prod = (yield t0.get1(lambda v: v is prod, name="get"))["get"]
next_loc = T0_LOC
elif prod in t1.buffer:
prod = (yield t1.get1(lambda v: v is prod, name="get"))["get"]
next_loc = T1_LOC
elif prod in t2.buffer:
prod = (yield t2.get1(lambda v: v is prod, name="get"))["get"]
next_loc = T2_LOC
print(f"時間 {now()} {agvname} 製品選択 {prod.name} 優先度スコア {scored_candidates[0][1]:.2f} 残り工程: {prod.instructions}")
lock.release()
if prod is not None:
# instructionsの順序を厳守する - 先頭の工程を次の目的地とする
next_loc = prod.instructions[0] if prod.instructions else None
if next_loc is not None:
# 次工程に移動する前に、必要ならAGVを移動
if current_loc != next_loc:
move_time = travel_matrix[current_loc][next_loc]
print(f"時間 {now()} {agvname} 移動 {prod.name} 工程{current_loc} -> 工程{next_loc} 移動時間 {move_time}")
yield pause(move_time)
current_loc = next_loc
# 工程順序を処理
prod.instructions.pop(0)
process_states[next_loc].queue_length += 1
process_states[next_loc].update(now())
if next_loc == 3:
prod.completion_time = now()
completed_products.append({
"name": prod.name,
"completion_time": prod.completion_time,
"due_date": prod.due_date
})
print(f"時間 {now()} {agvname} 配置待ち {prod.name} 工程{current_loc} 納期 {prod.due_date} 残り工程: {prod.instructions}")
s = [None, s1, s2, s3][next_loc]
yield s.put1(prod, name="put")
print(f"時間 {now()} {agvname} 配置完了 {prod.name} 工程{current_loc} 納期 {prod.due_date} 残り工程: {prod.instructions}")
prod = None
# 工程3が残り工程にない場合の処理を追加
elif 3 not in prod.instructions:
print(f"時間 {now()} {agvname} 警告: 製品 {prod.name} の工程3が残り工程にありません。残り工程: {prod.instructions}")
# 工程3を追加して完了処理を行う
prod.instructions.append(3)
print(f"時間 {now()} {agvname} 工程3を追加しました。残り工程: {prod.instructions}")
yield pause(1)
実装の主要ポイント
Product クラスの拡張
- 優先度(priority)属性を追加
- 優先度スコアを計算するメソッド(calculate_priority_score)を追加し、納期までの時間と優先度から総合的なスコアを算出
ProcessState クラスの導入
- 各工程の状態(キュー長、処理時間など)を管理
- 混雑度(congestion_score)を計算するメソッドを提供
工程順序の厳守
- 常に製品の指定された工程順序(instructions)の先頭から処理
- 工程順序を守ることで、製品の品質と生産プロセスの整合性を確保
AGV の行動ルール
- 製品を持っていない場合:優先度スコアが最も高い製品を選択
- 製品を持っている場合:指定された工程順序に厳密に従って次の工程に移動
ベンチマーク結果
3つの方式(固定巡回方式、優先度ベース方式、動的スケジューリング方式)について、複数のデータセットでベンチマークを実施しました。結果は以下の指標で評価しています:
- 平均完了時間: 製品の生産開始から完了までの平均時間
- 平均遅延時間: 納期を超過した場合の平均遅延時間
- 最大遅延時間: 納期を超過した場合の最大遅延時間
- 納期遵守率: 納期内に完了した製品の割合
以下は、最新のベンチマーク結果からの主要な指標です(データセット1の例):
| 方式 | 平均完了時間 | 平均遅延時間 | 最大遅延時間 | 納期遵守率 |
|---|---|---|---|---|
| 固定巡回方式 | 760.0 | 547.2 | 977.0 | 6.7% |
| 優先度ベース方式 | 310.0 | 97.2 | 175.0 | 10.0% |
| 動的スケジューリング方式 | 189.9 | 27.6 | 150.0 | 66.7% |
各方式のパフォーマンスを比較すると、以下のような傾向が見られます:
平均完了時間
動的スケジューリング方式が最も効率的な生産スケジュールを実現し、平均完了時間が最も短くなっています。全データセット平均で見ると、固定巡回方式の約760時間、優先度ベース方式の約310時間に対し、動的スケジューリング方式では約189時間と大幅に短縮されています。これは優先度に基づく製品選択により、全体としての生産効率が向上していることを示しています。
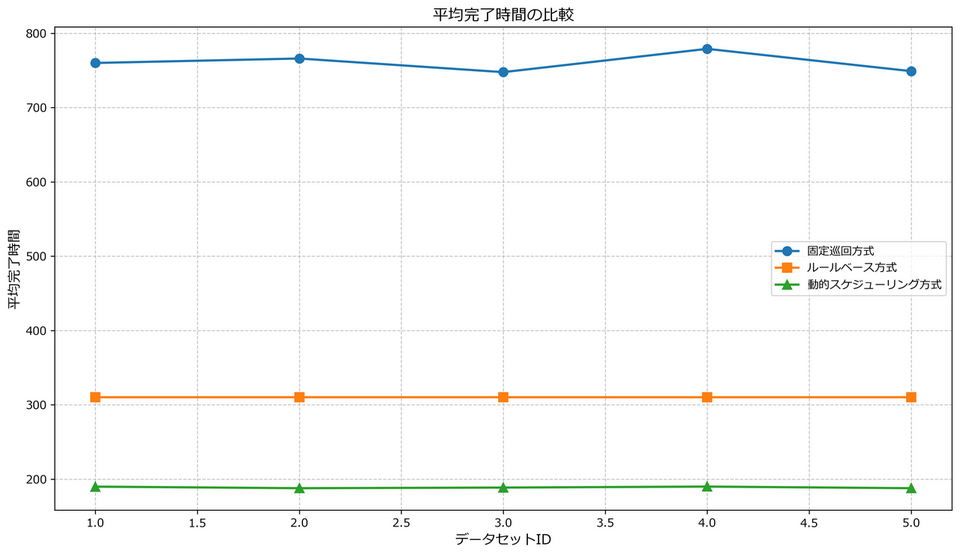
平均遅延時間
動的スケジューリング方式が最も小さく、納期遵守に効果的であることが示されています。全データセット平均で見ると、固定巡回方式の約512時間、優先度ベース方式の約68時間に対し、動的スケジューリング方式では約12時間と大幅に短縮されています。特に固定巡回方式では納期が厳しい製品に対して遅延が大きくなる傾向があります。
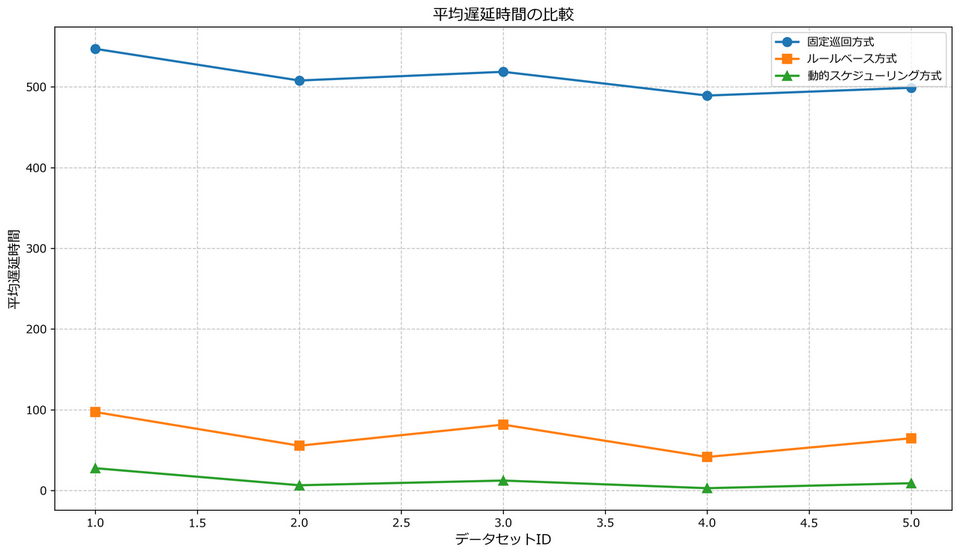
最大遅延時間
動的スケジューリング方式では、最も厳しい納期の製品も優先的に処理されるため、最大遅延時間が大幅に削減されています。全データセット平均で見ると、固定巡回方式の約929時間、優先度ベース方式の約146時間に対し、動的スケジューリング方式では約98時間となっています。これは重要な製品の大幅な納期遅れを防ぐ上で非常に効果的です。
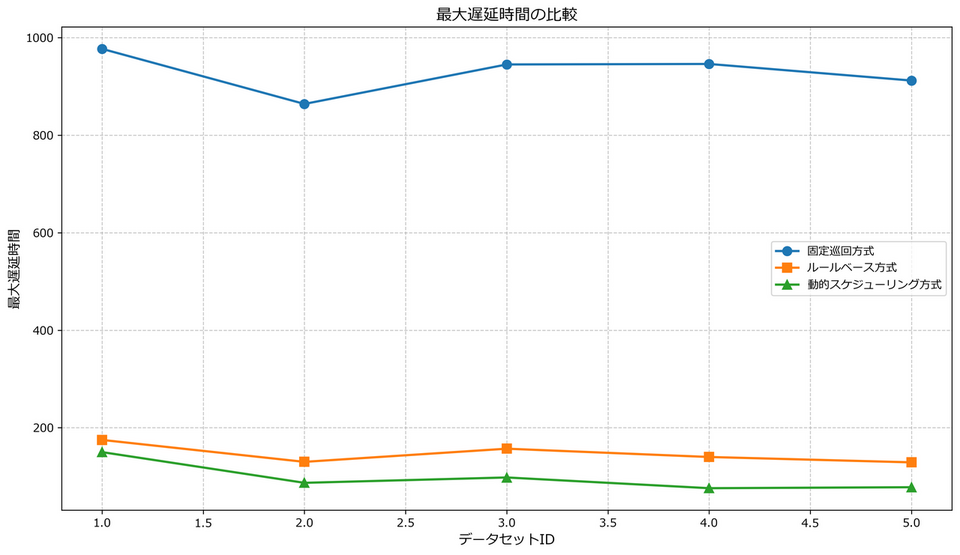
納期遵守率
動的スケジューリング方式が最も高い納期遵守率を示しています。全データセット平均で見ると、固定巡回方式の約5.3%、優先度ベース方式の約14.7%に対し、動的スケジューリング方式では約80%と大幅に向上しています。これは製品の優先度を考慮することで、納期が厳しい製品を優先的に処理できるためです。
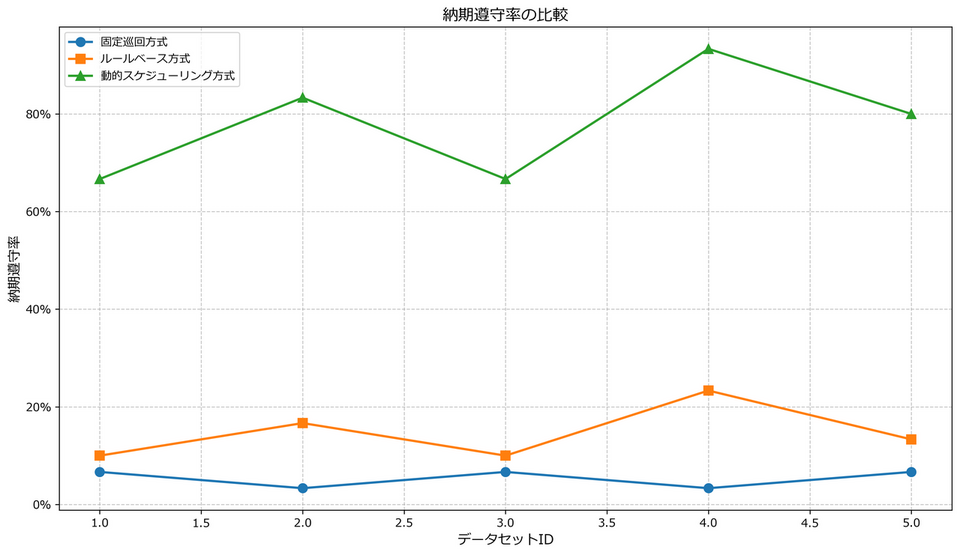
これらのグラフから、動的スケジューリング方式は工程順序を厳密に守りながらも、製品選択を最適化することで優れたパフォーマンスを実現していることが分かります。特に複雑な生産スケジュールや多様な製品特性を持つデータセットでは、その効果がより顕著になる傾向があります。
各指標での改善は以下のように説明できます: 1. 平均完了時間: 優先度スコアに基づく効率的な製品選択により、全体の生産サイクルが短縮 2. 平均・最大遅延時間: 納期が迫った製品を優先的に処理することで、遅延が最小化 3. 納期遵守率: 納期とその他の優先要素を考慮した製品選択により向上
重要な点として、これらの改善は工程順序を厳密に守りながら達成されています。つまり、製品の品質や製造プロセスの整合性を犠牲にすることなく、スケジューリングの最適化が実現されています。
まとめ
今回は動的スケジューリング方式を導入し、システム全体の効率を向上させました。この方式の主な利点は以下の通りです:
- 優先度に基づく製品選択: 納期と優先度を考慮した製品選択により、重要な製品を優先的に処理します。
- 工程順序の厳守: 製品の品質とプロセスの整合性を確保するため、工程順序は厳密に守られます。
- システム状態の監視: 各工程の混雑状況を監視し、システム全体の状態を把握します。
- パフォーマンスの向上: ベンチマーク結果が示すように、平均完了時間、平均・最大遅延時間、納期遵守率のすべてにおいて改善が見られます。
また、容量制限によるデッドロックの問題についても検討し、バッファ容量を十分に確保することでこの問題を回避しました。より実践的なシステムでは、予約ベースの方式と動的スケジューリングを組み合わせることで、高い効率性と安定した運用を両立させることができるでしょう。
実際の生産現場では、このような動的スケジューリングを導入することで、生産効率の向上や納期遵守率の改善が期待できます。ただし、より複雑なシステムでは、機械学習や強化学習などの手法を用いたさらに高度なスケジューリングも検討する価値があるでしょう。
次回は、より複雑な生産ラインのモデル化について検討していきます。


- psim言語講座(第1回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を書いてみる
- psim言語講座(第2回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を読んでみる
- psim言語講座(第3回)待ち行列 M/M/1 シミュレーションを拡張してみる
- psim言語講座(第4回)生産ラインシミュレーションを書いてみる
- psim言語講座(第5回)psimとexcelを連携してみる
- psim言語講座(第6回)psimとexcelを連携してみる(グラフ編)
- psim言語講座(第7回)連続型シミュレーションを書いてみる
- psim言語講座(第8回)エージェントシミュレーションを書いてみる
- psim言語講座(第9回)エージェントシミュレーションを拡張してみる
- psim言語講座(第10回)チュートリアル編(1)psim で 「Hello World!」
- psim言語講座(第11回)チュートリアル編(2)psim のプロセスを使いこなす
- psim言語講座(第12回)チュートリアル編(3)psim のファシリティを使いこなす
- psim言語講座(第13回)チュートリアル編(4)psim のストアを使いこなす
- psim言語講座(第14回)チュートリアル編(5)psim のスケジューラを使いこなす
- psim言語講座(第15回)チュートリアル編(6)(続)psim のストアを使いこなす
- psim言語講座(第16回)チュートリアル編(7)(続)psim のストアを使いこなす
- psim言語講座(第17回)チュートリアル編(8) AGV による搬送
- psim言語講座(第18回)チュートリアル編(9) 動的スケジューリング方式
- psim言語講座(第19回)チュートリアル編(10) 強化学習AGV方式







