- HOME
- 演算子学習(作用素学習)による代理ソルバー作成 - 物理法則を組み込んだ深層学習技術 (6)

更新日:2026年6月29日 11:39
公開日:2026年6月29日 10:00


はじめに
これまでの記事では、Physics-informed Neural Network(PINN)を用いた PDE(Partial Differential Equation、偏微分方程式)の解法を中心にご紹介してきました。実際の物理シミュレーションでは、様々な問題設定の PDE を何度も解く必要がある場合があります。例えば、以下のような状況が想定されます。
- 様々な境界条件でのシミュレーション:
製品の強度を評価するため、製品に様々な外力がかかった場合の応力分布をシミュレーションする状況。 - 様々な初期条件でのシミュレーション:
台風の進路予測で、観測された現在の台風の位置を元に将来の位置をシミュレーションする状況。
上記のような多数回の求解が必要な状況では、有限要素法や差分法を用いる通常の数値ソルバーや PINN による PDE の求解では、問題設定が変わるごとに、その都度、高コストな逆行列演算やニューラルネットワークの学習を行って解きなおす必要があります。
このよう状況では、機械学習モデルを用いた代理ソルバー(surrogate solver)を用意しておき、その推論によって解を求める方法が効率的です。モデルの入力は問題設定(係数、境界条件、初期条件等)であり、出力はその問題設定での PDE の解で、いずれも関数になります。関数から関数へのマッピングは演算子(Operator、作用素)と呼ばれるため、このようなマッピングの学習を演算子学習(Operator Learning、作用素学習)[1] [2] と呼びます。
本記事では、機械学習モデルを用いた代理ソルバー作成へのアプローチとして、近年注目を集めている演算子学習について解説します。まず、演算子学習とは何か の節で基本的なアイデアを説明した後、演算子学習のアーキテクチャ の節で、代表的なアーキテクチャを紹介します。数値実験 の節では、簡単な数値実験の結果をご紹介します。
- 演算子学習とは何か
- 演算子学習のアーキテクチャ
- DeepGreen
- Deep Operator Network
- Neural Operator
- 数値実験
- 問題設定
- モデル作成設定
- 結果
- まとめ
演算子学習とは何か
従来のニューラルネットワークは、数値ベクトルから数値ベクトルへの写像(関数)を学習します。これに対し、演算子学習では、関数から関数への写像(演算子)を学習します。コンピュータでデータを扱う以上、入力が離散的なグリッド(画素やメッシュ)の形式になるのは、従来の教師あり学習も演算子学習も一見同じです。しかし、内部で行われている計算の思想が根本的に異なります。
通常の教師あり学習(CNN や MLP など)
入力されたグリッドを「バラバラの独立した数値の集まり(ドットの並び)」として処理します。学習されるのは、これらのドットの並びの規則(どこのセルが黒の時はどこのセルが黒になるか、といった規則)であり、そのため、学習時と異なる解像度(グリッドサイズ)のデータが来ると破綻してしまいます。前処理で縮尺(リサイズ)を合わせたとしても、それはデータの形を局所的な情報を使いモデルの枠に無理やり合わせているだけであり、データを全体として一つのものとして取り扱ってはおらず、背後にある普遍的な法則を学べる保証はありません。
演算子学習(FNO や DeepONet など)
入力されたグリッドを連続な関数をデジタルにサンプリングしたものとして捉えます。モデルの内部で点と点の間にある連続的な関係性(構造)を維持したまま計算を行うため、偏微分方程式の背後にある物理法則の学習が可能になります。そのため、推論時に学習時と異なる解像度のデータが来たとしても、破綻することなく推論することが出来ます。
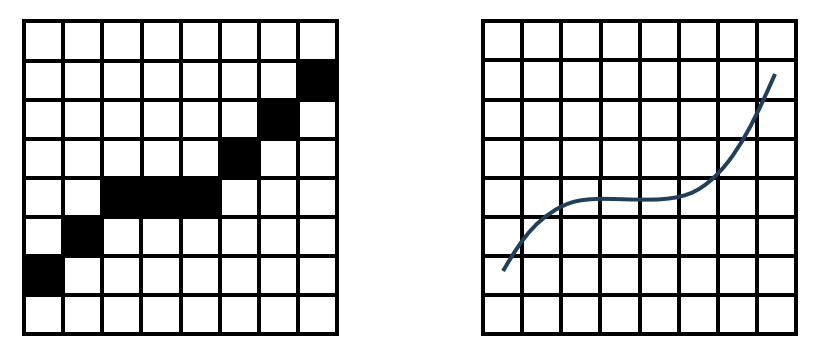
従来の教師あり学習と演算子学習の最大の違いは、未知のデータに対する汎化性能にあります。通常の教師あり学習モデルは、訓練データと似たデータの予測(内挿)は得意ですが、未知のデータの予測(外挿)は不得手です。これは、教師あり学習のモデルが現象の見た目のパターン(相関関係)を記憶して帳尻を合わせるショートカット学習に陥りやすいためです。訓練データに対しては、出力が一見正しいように見えても、物理的に妥当でない規則を学習しているので、未知のデータへの汎化性能は低くなります。一方で、演算子学習は、データの表面的な見た目ではなく、データの背後にある物理法則そのものを学習できるため、未知のデータに対しても、物理的に正しい予測(外挿)が可能で、高い汎化性能を発揮することが期待されます。
演算子学習は入力を関数として処理し、正しい物理法則を学習するために、解のグリーン関数(カーネル)表示に基づく独自のアーキテクチャを採用しています [3]。まず、以下の線形偏微分方程式を考えます。
[[ \mathcal{L}u = f. ]]
この方程式の解は、グリーン関数(カーネル)を用いて以下の積分表示で表されます。
[[ u(x) = \mathcal{L}^{-1}f = \int_{\Omega} G(x,y) f (y)dy. ]]
この表式では、入力 $f$ をひとまとまりの関数として扱い、積分演算によって $f$ の空間全体での情報を解と関係づけています。グリーン関数 $G(x, y)$ をデータから学習することが、上記の線形問題の解演算子 $\mathcal{L}^{-1}$ の演算子学習に他なりません。
より一般的な(非線形の)偏微分方程式に対しても、カーネル法的に高次元の潜在空間を考え、そこで解を
[[ \text{Output}(x) = Q \circ \biggl(\int_{\Omega} \mathcal{K}(\hat{x}, \hat{y}) \bigl(P\circ\text{Input}\bigr)(\hat{y})d\hat{y} \biggr), \tag{1} ]]
のように表現します。$P$ は潜在空間への lifting operator、$Q$ は潜在空間からの projection operator、$\mathcal{K}(x, y)$ は潜在空間でのグリーン関数(カーネル)です。これら $P, Q, \mathcal{K}$ をデータから学習することで、一般の偏微分方程式の解演算子の演算子学習を行います。線形問題の場合と同様に(そして通常の機械学習とは異なり)、入力 $\text{Input}(y)$ はひとまとまりの関数として扱われ、空間全体の情報が活用されています。
特に、カーネル $\mathcal{K}$ を $\mathcal{K}(x,y) = \sum_i \lambda_i \psi_i(x)\psi_i(y)$ のように基底関数展開すると、出力に対する表式は($P, Q$ を省略して)
[[ \text{Output}(x) = \sum_i \lambda_i \psi_i(x) \biggl( \int_{\Omega}\psi_i(y)\;\text{Input}(y)dy \biggr), \tag{2} ]]
となり、単に回帰係数 $\lambda_i$ を学習すればよいことになり、学習が効率的に行えます。
以上のカーネル(および基底関数展開)を用いたアプローチにより、モデルは全点間の関係性をバラバラの数値として丸暗記するのではなく、空間全体の連続的なつながりとして数式化して保持します。
次節で、演算子学習の代表的なアーキテクチャを紹介します。
演算子学習のアーキテクチャ
演算子学習で用いられる代表的なアーキテクチャとしては、(1) DeepGreen、(2) Deep Operator Network (DeepONet)、(3) Neural Operator があります。いずれも前節で説明したカーネル表示(および基底関数展開)に基づくアーキテクチャですが、何をニューラルネットワークでモデル化するか、カーネルの基底関数の選び方、などに違いがあります。以下ではそれぞれのアーキテクチャについて説明します。学習したい演算子を $\mathcal{G}$ と表記し、その入力を $u$、出力を $v = \mathcal{G}[u]$と表記します。
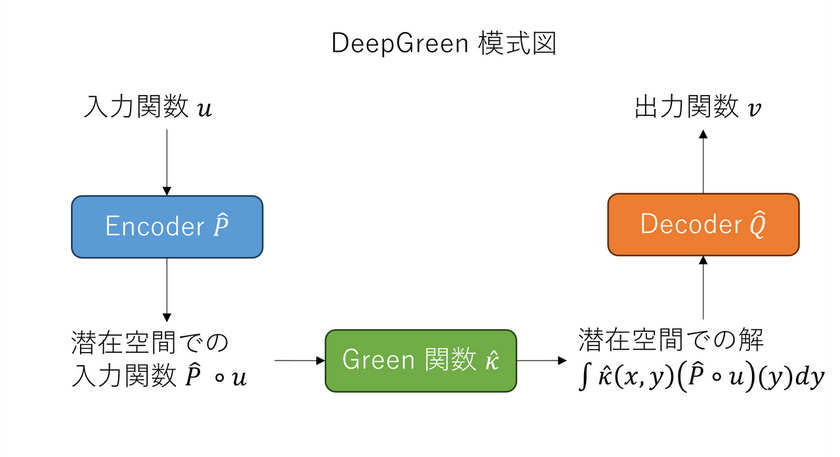
DeepGreen
DeepGreen [4] は、式 (1) に基づく演算子学習のアーキテクチャです。DeepGreen では、非線形な偏微分方程式の解演算子を以下のアーキテクチャ $\hat{P}, \hat{\mathcal{K}}, \hat{Q}$ の組み合わせでモデル化します:
[[ v = \mathcal{G}[u] = \hat{Q}\circ\biggl( \int_{\Omega} \hat{\mathcal{K}}(\hat{x}, \hat{y}) \bigl(\hat{P}\circ u\bigr)(\hat{y}) d\hat{y} \biggr). ]]
ここで、$\hat{P}$ は潜在空間への encoder 、$\hat{Q}$ は潜在空間からの decoder であり、それぞれニューラルネットワークでモデル化します。そして、潜在空間でのカーネル(グリーン関数)$\hat{\mathcal{K}}$ 自体もニューラルネットワークでモデル化します。カーネルの基底関数展開は用いていません。
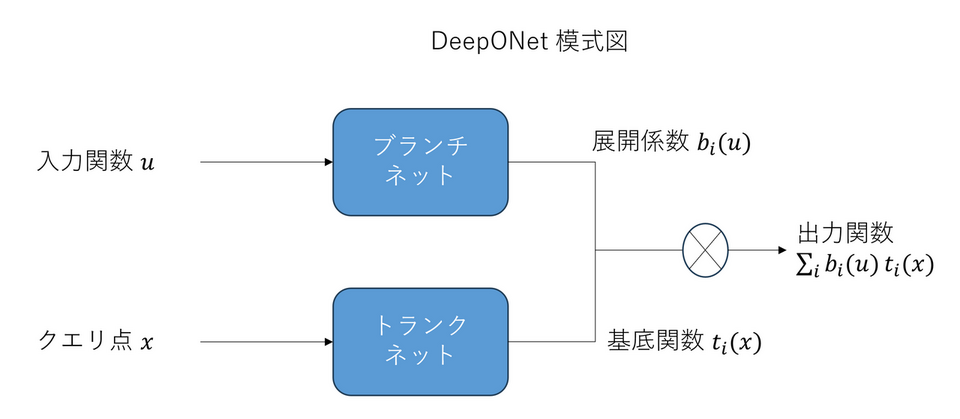
Deep Operator Network
Deep Operator Network (DeepONet) [5] は式 (2) の基底関数展開に基づく演算子学習のアーキテクチャです。ただし、予め決まった基底関数を用いるのではなく、基底関数自体もニューラルネットワークで学習します。また、潜在空間は特に用いていません。DeepONet を数式で表すと、以下の通りとなります。
[[ v(x) = \mathcal{G}[u](x) = \sum_{i=1}^{p}b_i(u; \theta_b) t_i(x; \theta_t). ]]
アーキテクチャは 2 つのネットワークから構成され、それぞれをブランチネット、トランクネットと呼びます。、$b_i(u; \theta_b)$ はブランチネットを表し、$\theta_b$ はそのパラメータです。ブランチネットは、入力関数を展開係数 $b_i(u; \theta_b)$ にマップします。一方、$t_i(x; \theta_t)$ はトランクネットを表し、$\theta_t$ はそのパラメータです。トランクネットは、ニューラルネットワークによって表現された、 解を展開する際の基底関数です。ハイパーパラメータ $p$ は用いる基底関数の個数です。
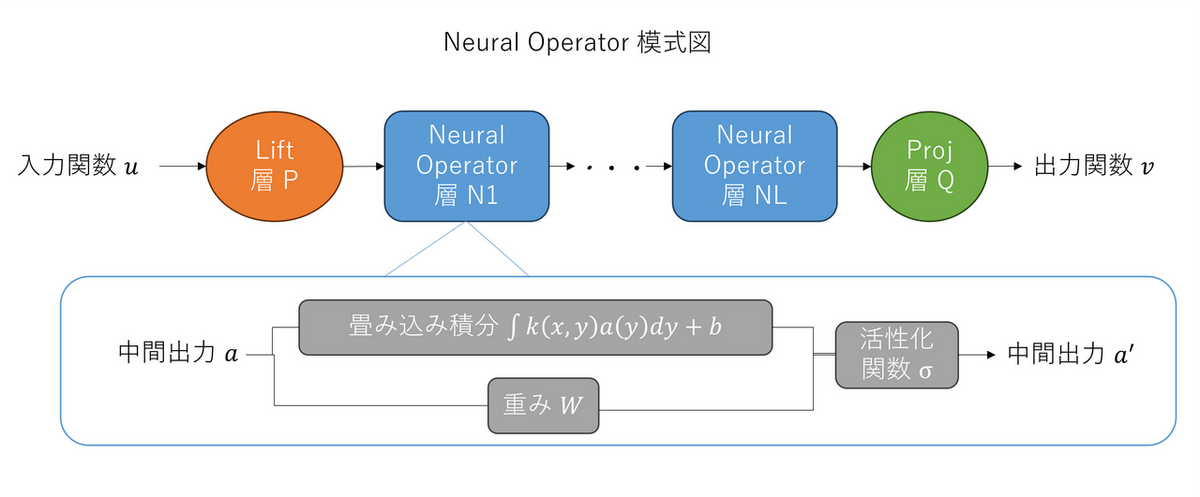
Neural Operator
Neural Operator (NO) [6] は、DeepOnet と同様に、式 (2) の基底関数展開に基づく演算子学習のアーキテクチャです。ただし、NO では単に 1 回カーネル積分を行うのではなく、通常のニューラルネットワークのアーキテクチャをまねて、複数回のカーネル積分を、(非線形な)活性化関数、重み、バイアスと組み合わせます。
入力と出力の関係は以下の式となります:
[[ \begin{aligned} v = \mathcal{G}[u] &= \mathcal{Q} \circ \mathcal{L}_L \circ \cdots \circ \mathcal{L}_1 \circ \mathcal{P}(u),\\ \mathcal{L}_l[v] &= \sigma \biggl(\hat{W}_l v + \hat{b}_l +\int_{\Omega} \hat{\mathcal{K}}_l(x, y)v(y)dy\biggr). \end{aligned} ]]
ここで、$\mathcal{P}$ および $\mathcal{Q}$ は、潜在空間への lifting/projection であり、通常は単なる線形変換とします。アーキテクチャの主要なコンポーネントは $\mathcal{L}_l$ であり、これは入力 $v$ に対するカーネル積分に加えて、通常のニューラルネットワークの隠れ層を模倣した項 $\sigma, \hat{W}_l, \hat{b}_l$ を付け加えています。$\sigma$ は(非線形の)活性化関数、$\hat{W}_l$ は重み、$\hat{b}_l$ はバイアスです。重み、バイアスはデータから学習します。$\hat{\mathcal{K}}_l$ はカーネルで、これを展開する際の基底関数の取り方を様々に変えることで、様々な NO のアーキテクチャが得られます。具体的には以下のものがあります。
- Fourier Neural Operator (FNO) [7]:このアーキテクチャでは、カーネル $\hat{\mathcal{K}}_l$ を三角関数を用いて展開します。この時、フーリエ変換を $\mathcal{F}$、逆フーリエ変換を $\mathcal{F}^{-1}$ とすると、$l$ 番目の隠れ層によるカーネル変換は以下の式となります。$R_l$ はパラメータ行列であり、その値を学習によって決定します。
[[ \int_{\Omega} \hat{\mathcal{K}}_l(x, y)v(y)dy = \mathcal{F}^{-1}(R_l \cdot \mathcal{F}(v)). ]]
Wavelet Neural Operator (WNO) [8]:このアーキテクチャでは、カーネル $\hat{\mathcal{K}}_l$ を三角関数の代わりにウェーブレット基底を用いて展開します。FNO のフーリエ変換と逆フーリエ変換の代わりに、ウェーブレット変換と逆ウェーブレット変換を用いることになります。
Operator Transformer [9]:このアーキテクチャでは、カーネル積分を以下の transformer の連続版によって実行します。FNO や WNO とは異なり、カーネルが $x, y$ だけでなく $v(x), v(y)$ に依存する形に一般化されています。パラメータ $A_l, B_l, R_l$ の値を学習によって決定します。
[[ \int_{\Omega} \hat{\mathcal{K}}(v(x), v(y), x, y)v(y)dy = \int_{\Omega} \frac{\exp(\frac{\langle A_lv(x), B_l v(y)\rangle}{\sqrt{m}})}{\int_{\Omega} \exp(\frac{\langle A_l v(s), B_l v(y)\rangle}{\sqrt{m}})ds}R_lv(y)dy . ]]
数値実験
本節では、簡単なシミュレーション問題の代理ソルバーを演算子学習を用いて作成しました。
問題設定
感染症における感染可能者数 $S(t)$ と感染者数 $I(t)$ の推移を記述する以下の SIR モデルをシミュレーション対象としました。
[[ \begin{align*} \frac{dS}{dt} &= - \beta u_0(t) S(t)I(t),\\ \frac{dI}{dt} &= \beta u_0(t) S(t)I(t) - \mu u_1(t) I(t).\end{align*} ]]
ただし、$\beta$ は感染症の感染率のスケール、$\mu$ は感染症の回復率のスケールです。$u_0(t)$ が感染率の時間変動、$u_1(t)$ が回復率の時間変動となります。初期値については、感染可能者数の初期値 $S_0$ は $1000$ で固定とし、感染者数の初期値 $I_0$ は様々に変えてシミュレーションを行いました。シミュレーションの最大時間は $t_{max}=100.0$、タイムスタンプ数は $1000$ としました。
なお、各種係数の設定は以下の通りとしました。感染率と回復率の時間変動に対しては、➀三角関数、➁区分定数関数、のそれぞれの場合を試しました。
| 項番 | パラメータ | 説明 | 生成方法 |
|---|---|---|---|
| 1 | $I_0$ | 感染者数の初期値 | $[1, 50]$ の範囲でランダムに選択 |
| 2 | $\beta$ | 感染率のスケール | $[0.0002, 0.001]$ の範囲で一様ランダムに生成 |
| 3 | $\mu$ | 回復率のスケール | $[0.05, 0.2]$ の範囲で一様ランダムに生成 |
| 4 | $u_0(t)$ | 感染率の時間変動 |
① 三角関数: $u_0(t)= u_0 + \sum_{k=1}^{n} a_k \sin(2 \pi \omega_k t/t_{max}) + b_k \cos (2 \pi \omega_k t/{t_{max}})$ ・$n$ は $[2, 10]$ をランダムに選択 ・$a_k, b_k$ は $[-1.0, 1.0]$ の範囲で一様ランダムに生成 ・$\omega_k$ は $[0.1, 2.0]$ の範囲で一様ランダムに生成 ・$u_0$ は $[-0.5, 0.5]$ の範囲で一様ランダムに生成 ② 区分定数関数: $u_0(t)= \sum_{k=1}^{n} u_k 1_{[a_{k-1}, a_k]}(t)$ ・$n$ は $[2, 10]$ をランダムに選択 ・$a_k$ は $a_0 = 0, a_n = t_{max}$ とし、残りを $(0, t_{max})$ から一様ランダムに生成 ・$u_k$ は $[0, 1.0]$ の範囲で一様ランダムに生成 |
| 5 | $u_1(t)$ | 回復率の時間変動 | $u_0(t)$ と同じ方法で独立に生成 |
モデル作成設定
シミュレーターの代理モデルとしては、$(I_0, \beta, \mu, u_0(t), u_1(t))$ を入力とし、$(S(t), I(t))$ を出力とするモデルを、(1) MLP、(2) DeepOnet、(3) FNO、 (4) WNO のそれぞれで作成しました。アーキテクチャのサイズは以下の通りで、パラメータ数が概ね同じとなるように設定しました。
| 項番 | アーキテクチャ名 | サイズ | パラメータ数 |
|---|---|---|---|
| 1 | MLP | 幅 40、隠れ層の数 4 | 286960 |
| 2 | DeepONet |
Branch Net:幅 48、隠れ層の数 4 Trunk Net:幅 64、隠れ層の数 4 モード数:64 |
274306 |
| 3 | FNO | 幅 40、隠れ層の数 3、モード数:60 | 298666 |
| 4 | WNO | 幅 80、隠れ層の数 4、Wavelet 変換のレベル:8 | 270306 |
また、学習の際のハイパーパラメータの設定は以下の通りとしました。性能検証の際は、学習データを用いてモデルを学習し、検証データに対する損失が最小となるモデルでテストデータの性能を検証しています。
| 項番 | ハイパーパラメータ | 設定値 |
|---|---|---|
| 1 | オプティマイザー | Adam |
| 2 | 学習率 | 0.001 |
| 3 | バッチサイズ | 16 |
| 4 | スケジューラー | ReduceLROnPlateau (factor: 0.5, patience: 10) |
| 5 | エポック数 | 200 |
| 6 | データ数 | 学習: 4000, 検証: 1000, テスト: 1000 |
| 7 | 損失関数 | MSE |
結果
三角関数の時間変動の場合
$u_0(t), u_1(t)$ の時間変動が三角関数の場合に、$S(t), I(t)$ の予測値の RMSE は以下のようになりました。最良のケースを太字で示しています。
これによると、テストデータの RMSE は FNO < WNO < DeepONet < MLP となっています。FNO が最良の性能となるのは、$u_0(t), u_1(t)$ の時間変動として、三角関数の重ね合わせを用いたためと考えられます。実際、次に見るように、区分定数関数の場合は FNO は大きく性能が下がってしまいます。
| RMSE | 学習データ | 検証データ | テストデータ |
|---|---|---|---|
| $S(t)$ |
MLP:25.46 DeepONet:21.67 FNO:6.03 WNO:8.61 |
MLP:42.87 DeepONet:41.01 FNO:23.41 WNO:34.47 |
MLP:45.18 DeepONet:42.63 FNO:24.04 WNO:33.58 |
| $I(t)$ |
MLP:23.40 DeepONet:20.04 FNO:4.33 WNO:6.91 |
MLP:37.37 DeepONet:36.34 FNO:17.55 WNO:28.21 |
MLP:39.33 DeepONet:38.32 FNO:17.69 WNO:26.56 |
テストデータに対する予測結果の例は以下の通りとなりました。確かに FNO は他のモデルより性能が良くなっています。
| モデル | サンプル1 | サンプル2 |
|---|---|---|
| MLP | 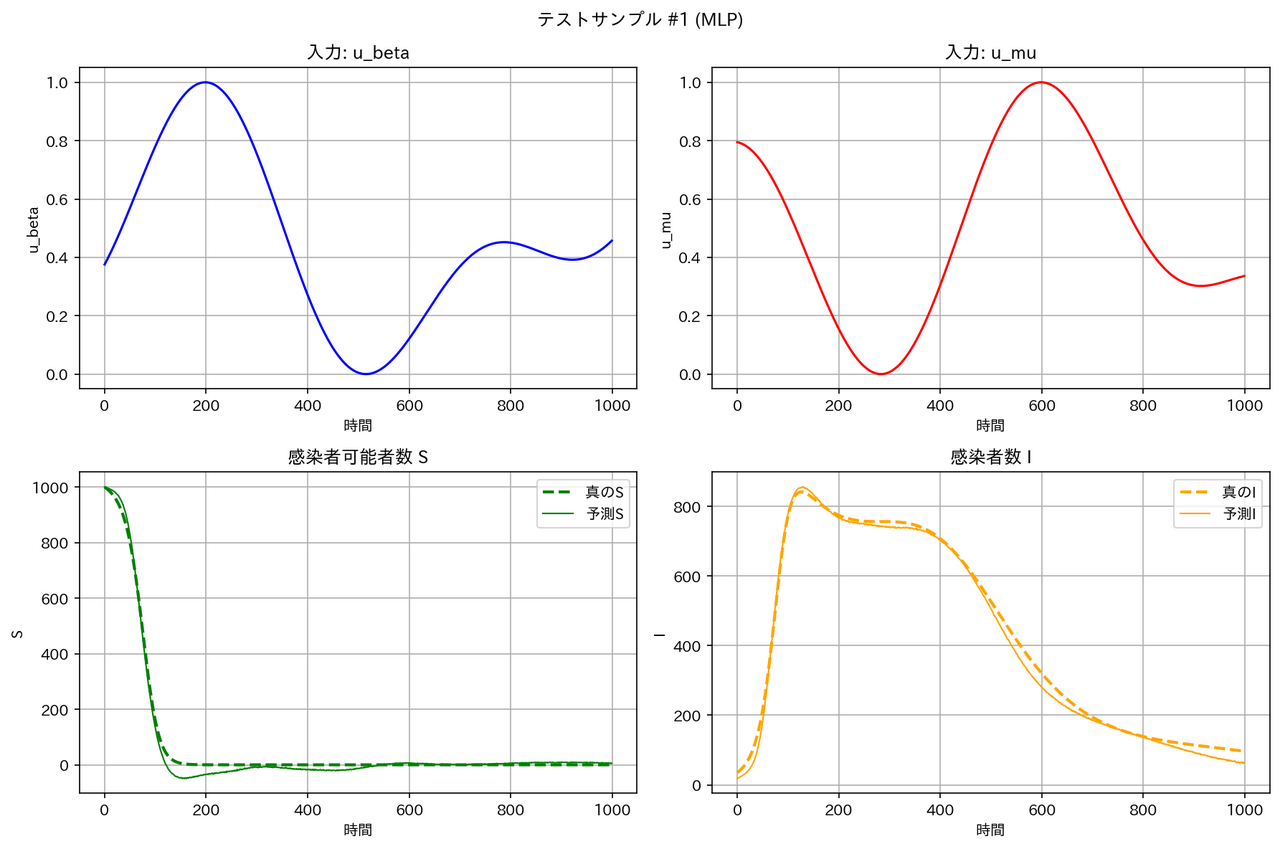 |
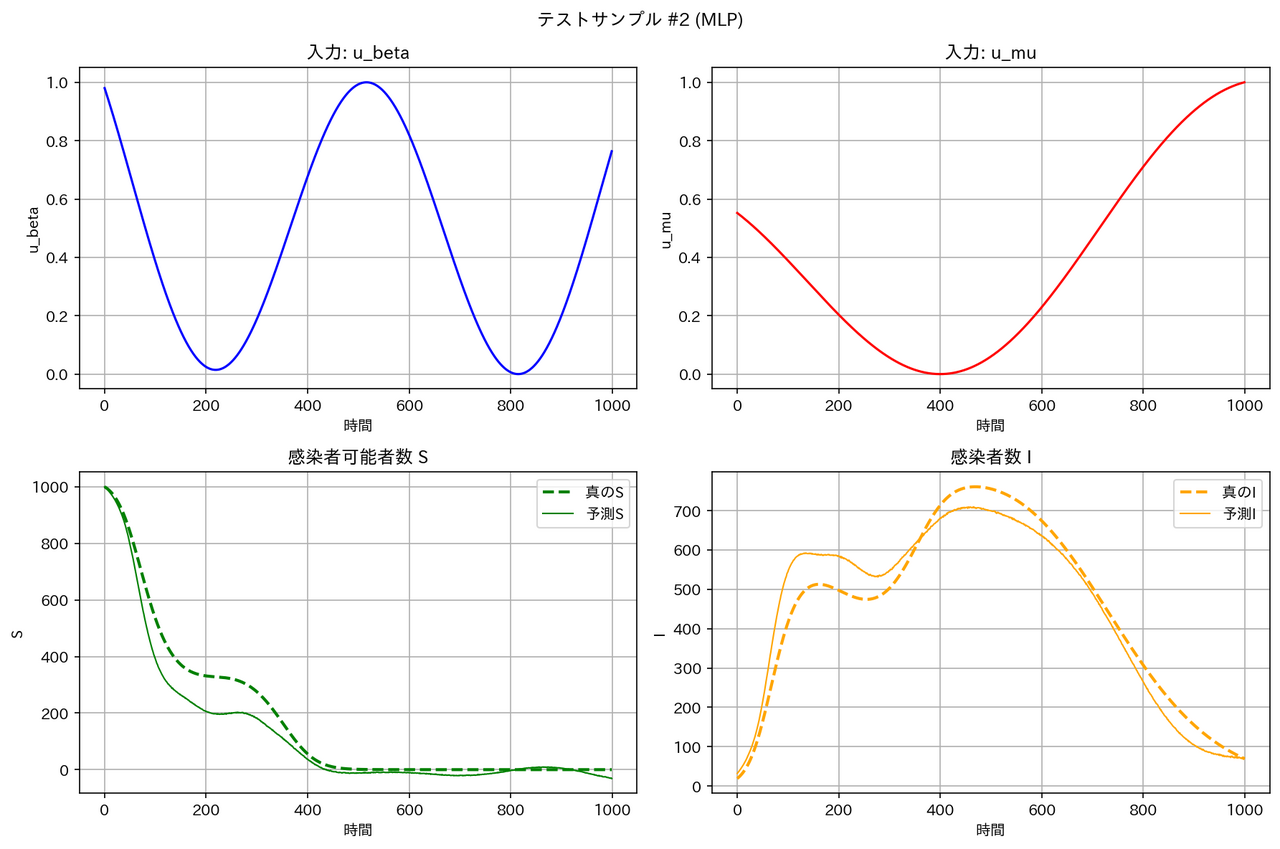 |
| DeepONet | 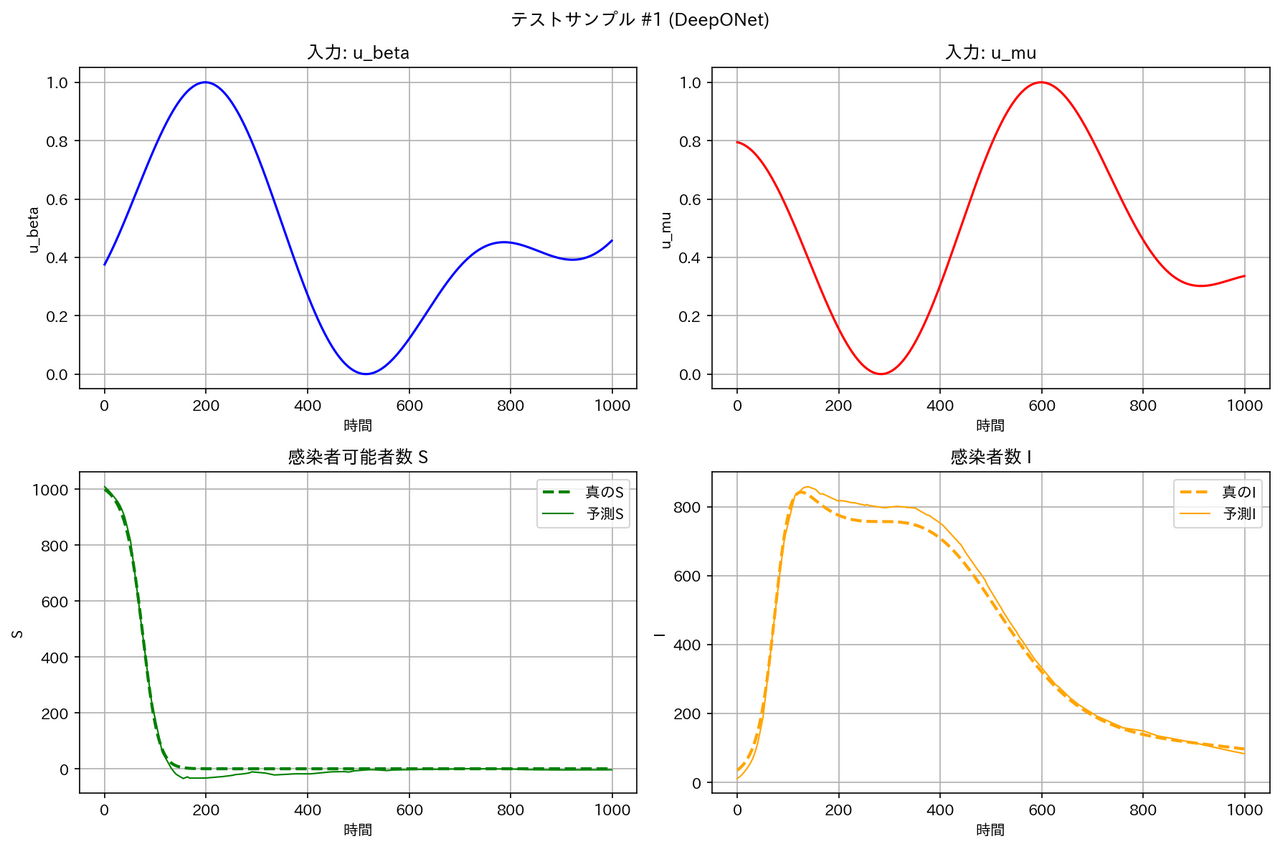 |
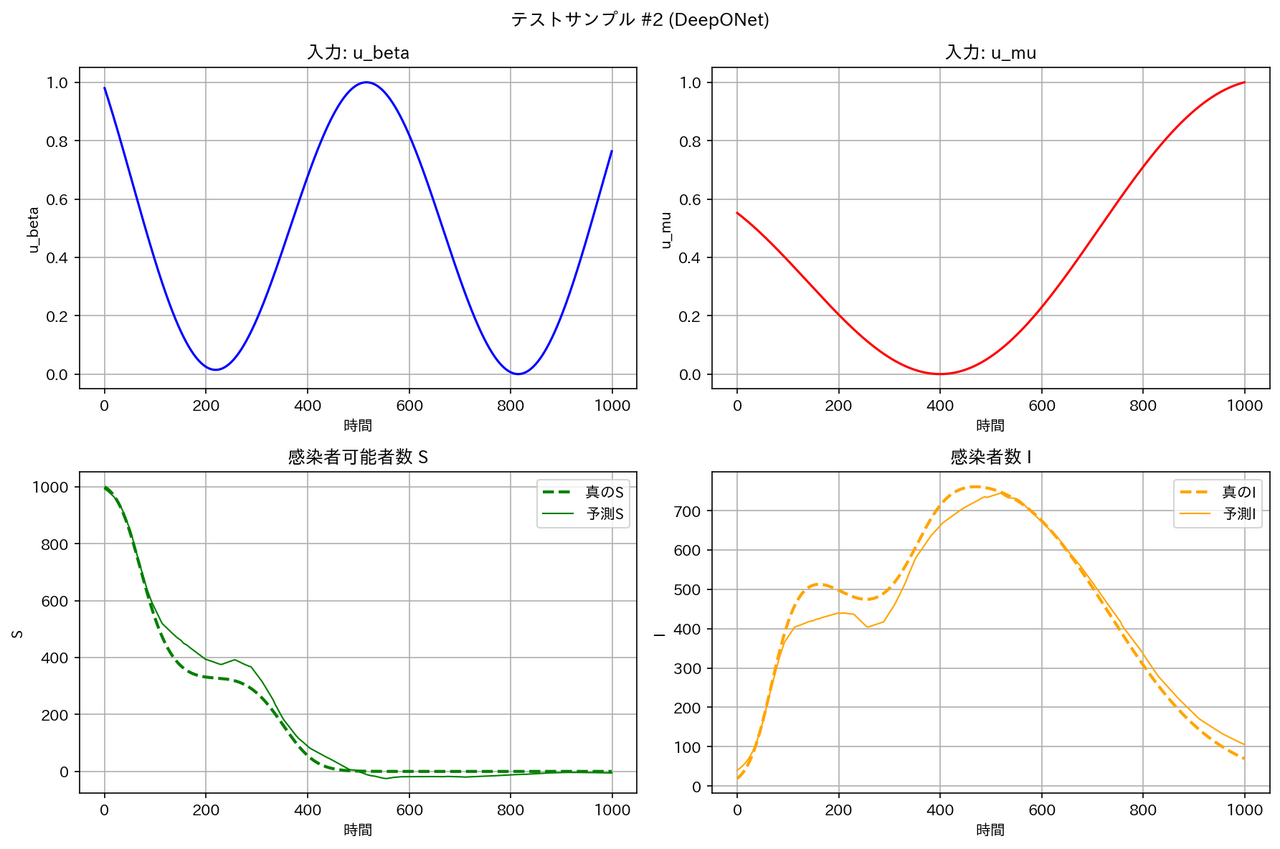 |
| FNO | 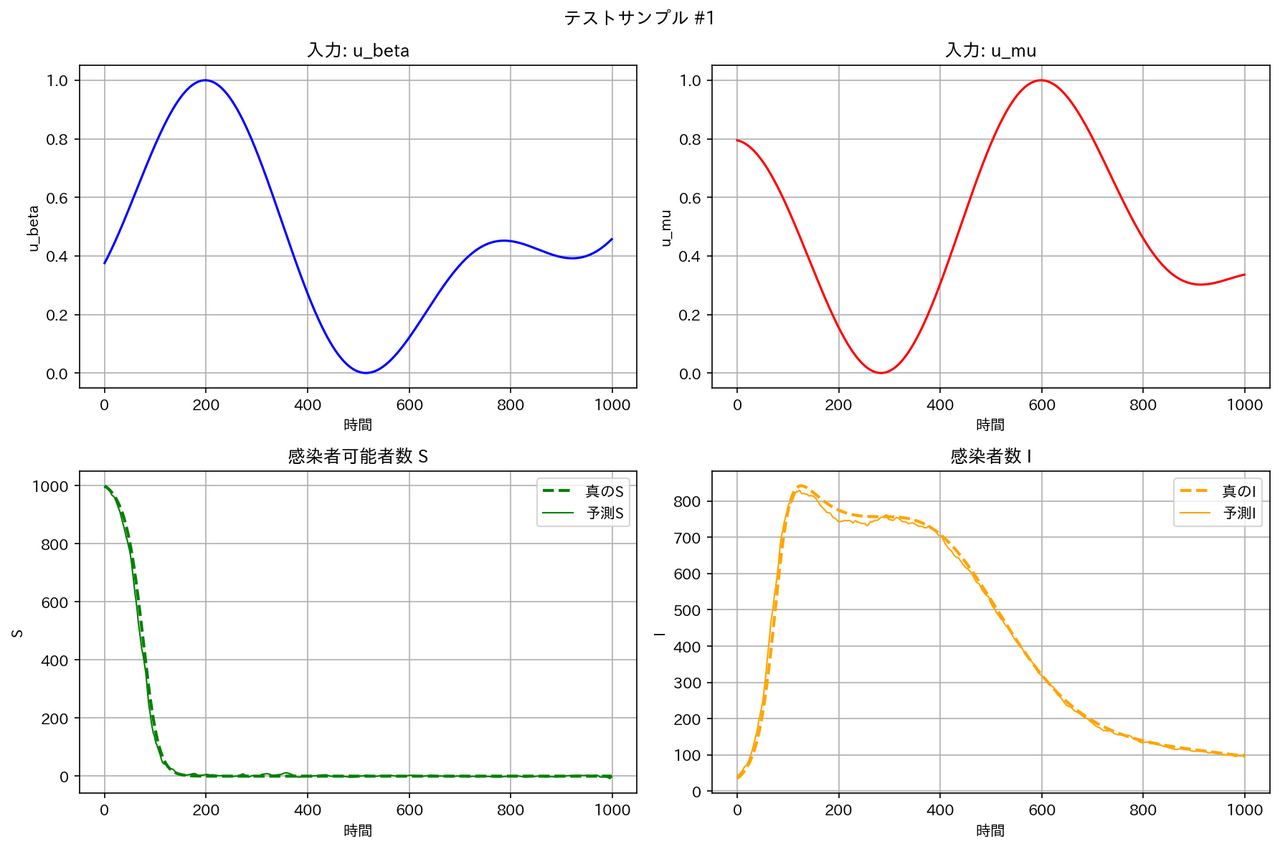 |
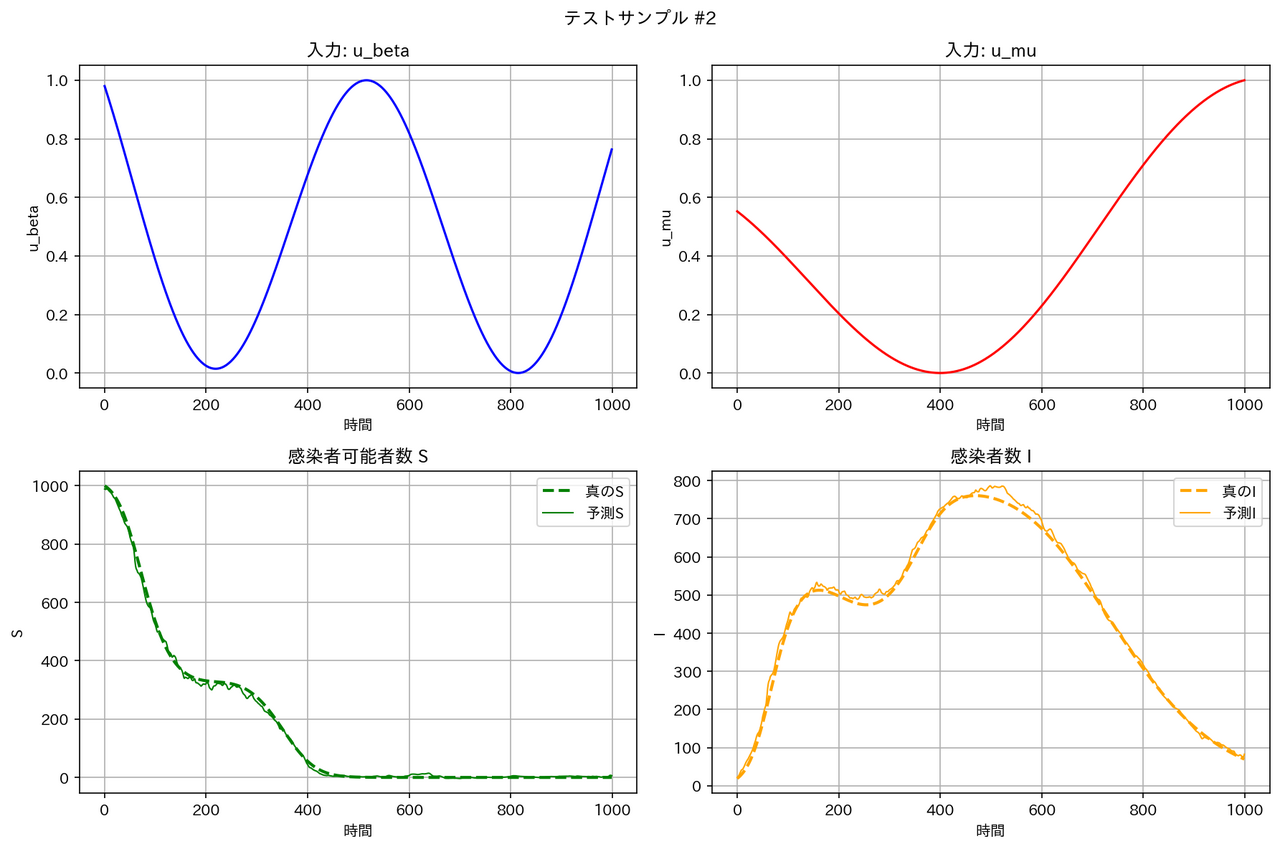 |
| WNO | 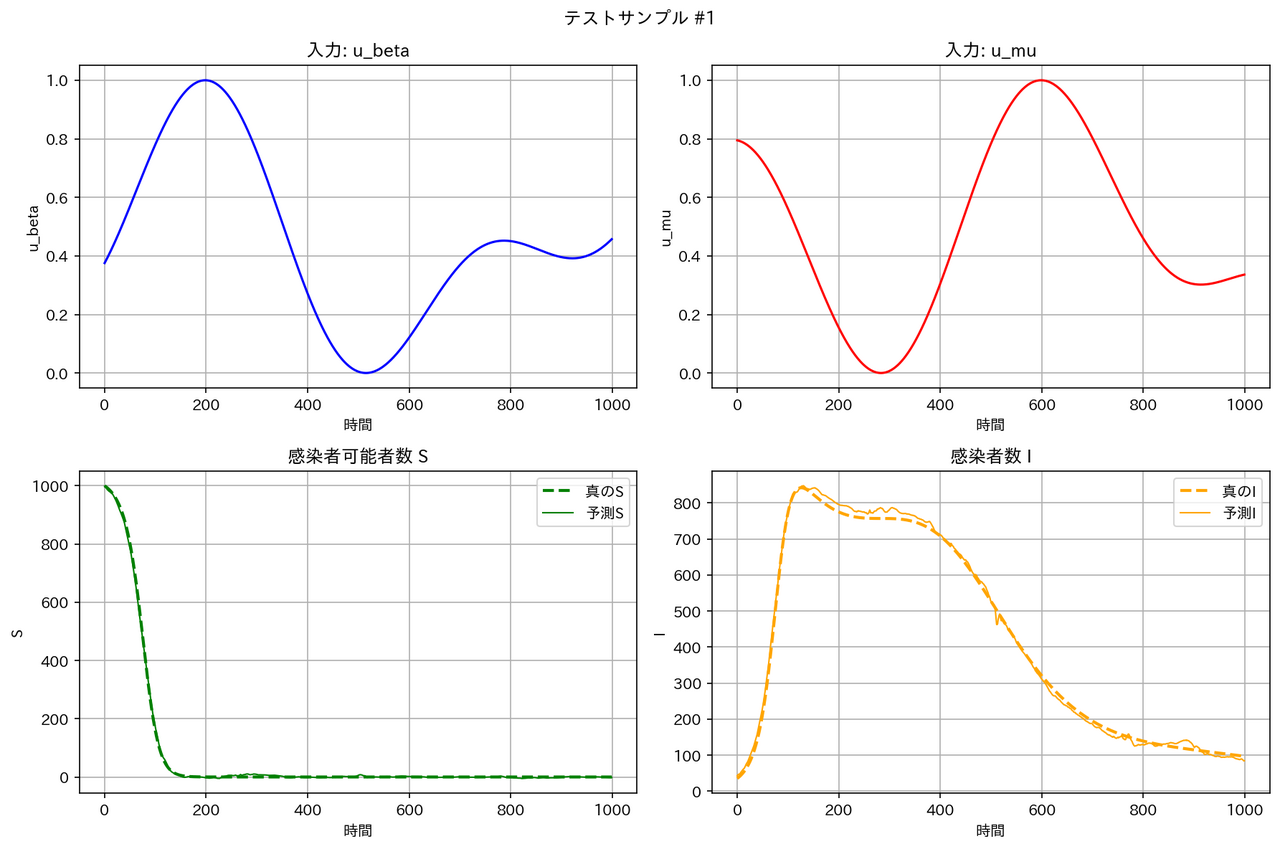 |
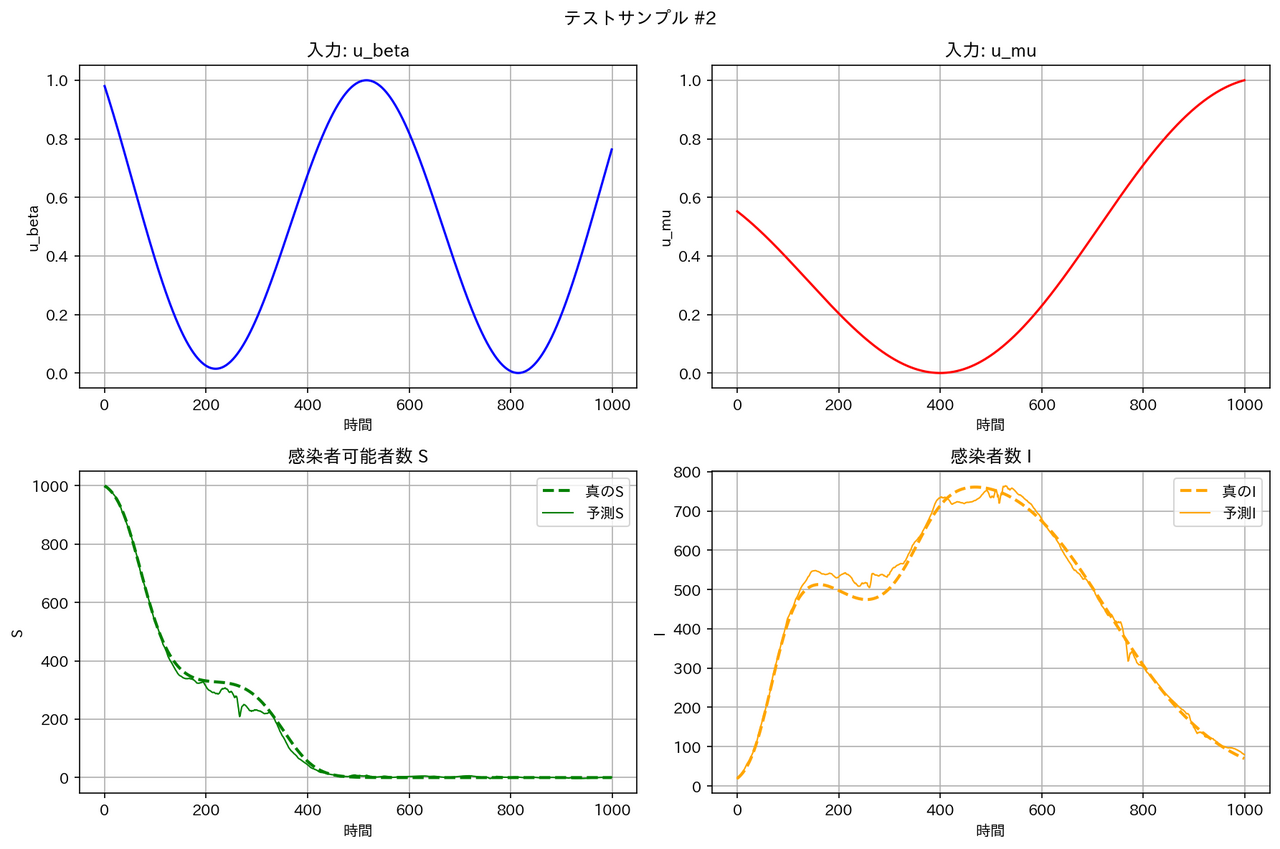 |
区分定数関数の時間変動の場合
$u_0(t), u_1(t)$ の時間変動が区分定数関数の場合に、$S(t), I(t)$ の予測値の RMSE は以下のようになりました。最良のケースを太字で示しています。
テストデータの RMSE は WNO < MLP < DeepONet << FNO となっています。区分線形関数については、一部の領域で急激な変化が起こるため、周期構造を持った三角関数を基底とする FNO は適しておらず、検証データとテストデータの性能が悪くなったと考えられます。一方、空間的に局在したウェーブレット基底を用いる WNO は、区分定数の時間変動を表現するのに適しており、最良の RMSE となったと考えられます。
| RMSE | 学習データ | 検証データ | テストデータ |
|---|---|---|---|
| $S(t)$ |
MLP:25.42 DeepOnet:24.80 FNO:52.27 WNO:7.92 |
MLP:52.90 DeepOnet:57.04 FNO:275.77 WNO:26.10 |
MLP:56.25 DeepOnet:60.03 FNO:278.90 WNO:28.39 |
| $I(t)$ |
MLP:23.70 DeepOnet:23.68 FNO:33.97 WNO:5.68 |
MLP:46.06 DeepOnet:48.21 FNO:155.27 WNO:22.96 |
MLP:48.31 DeepOnet:51.66 FNO:155.78 WNO:22.71 |
テストデータに対する予測結果の例は以下の通りとなりました。確かに WNO は他のモデルより性能が良くなっています。
| モデル | サンプル1 | サンプル2 |
|---|---|---|
| MLP | 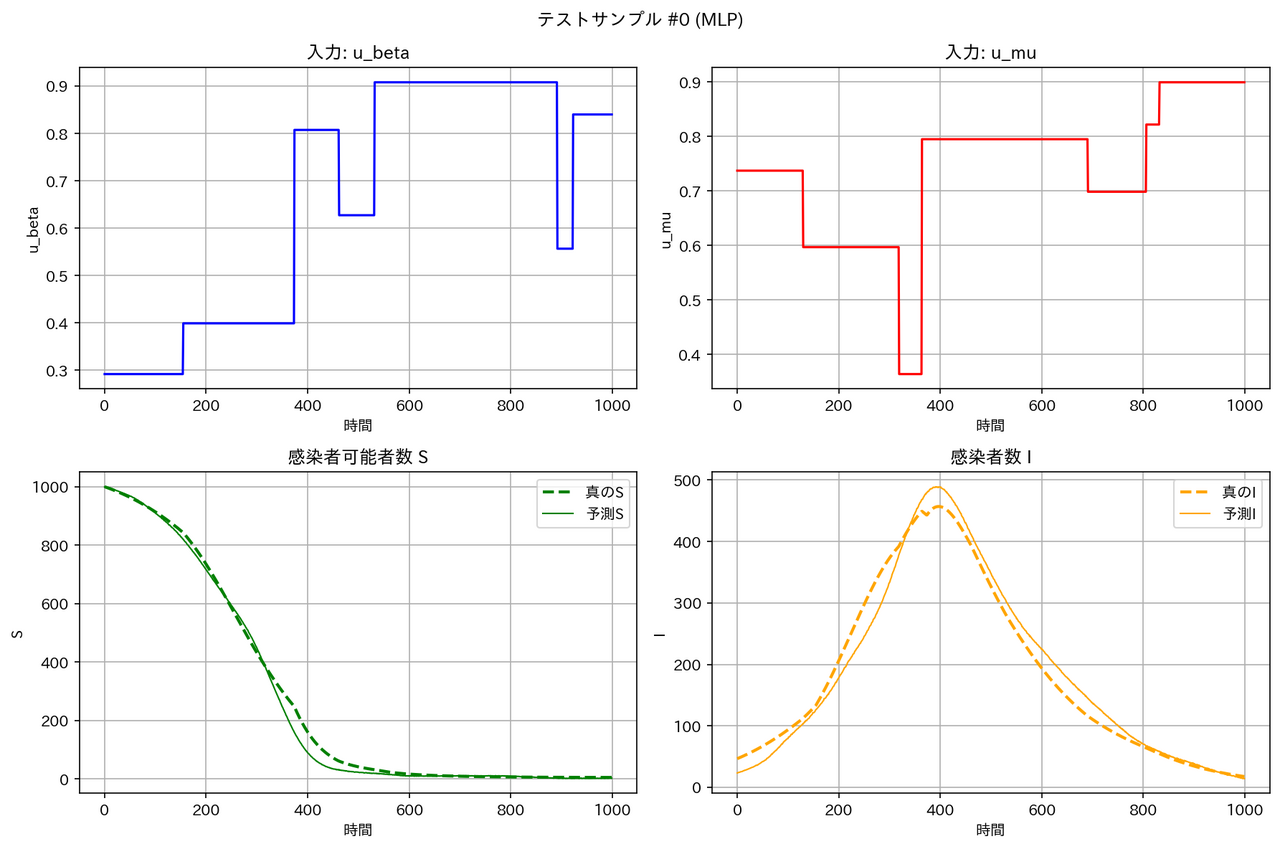 |
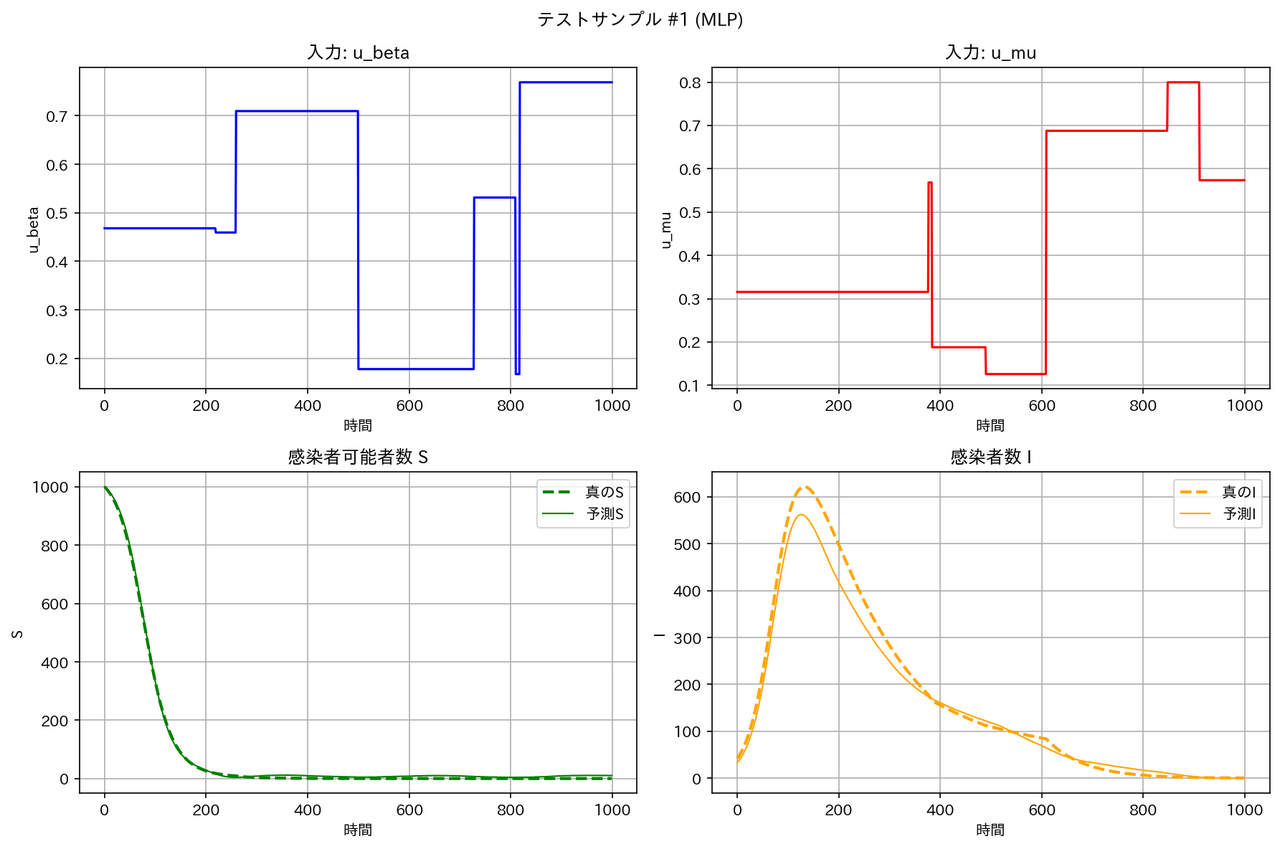 |
| DeepONet | 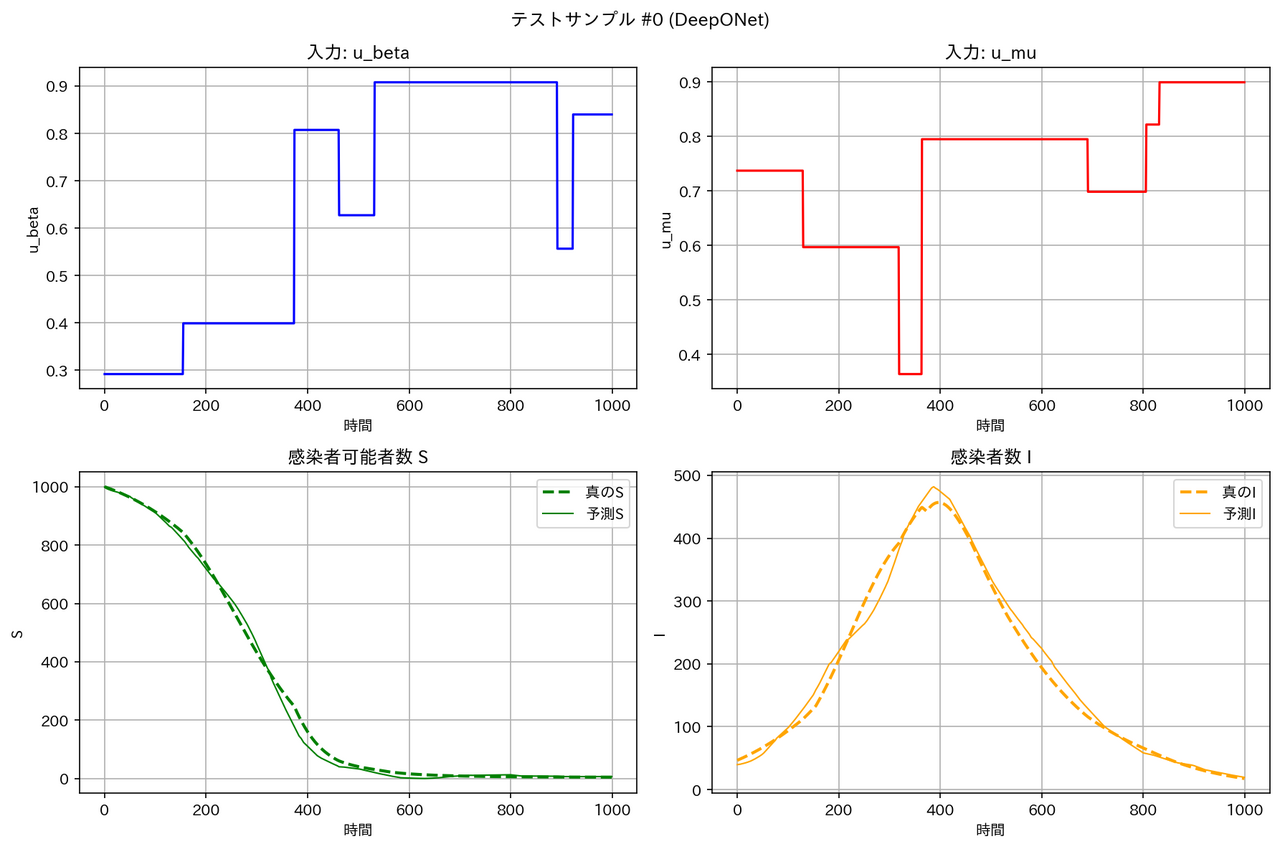 |
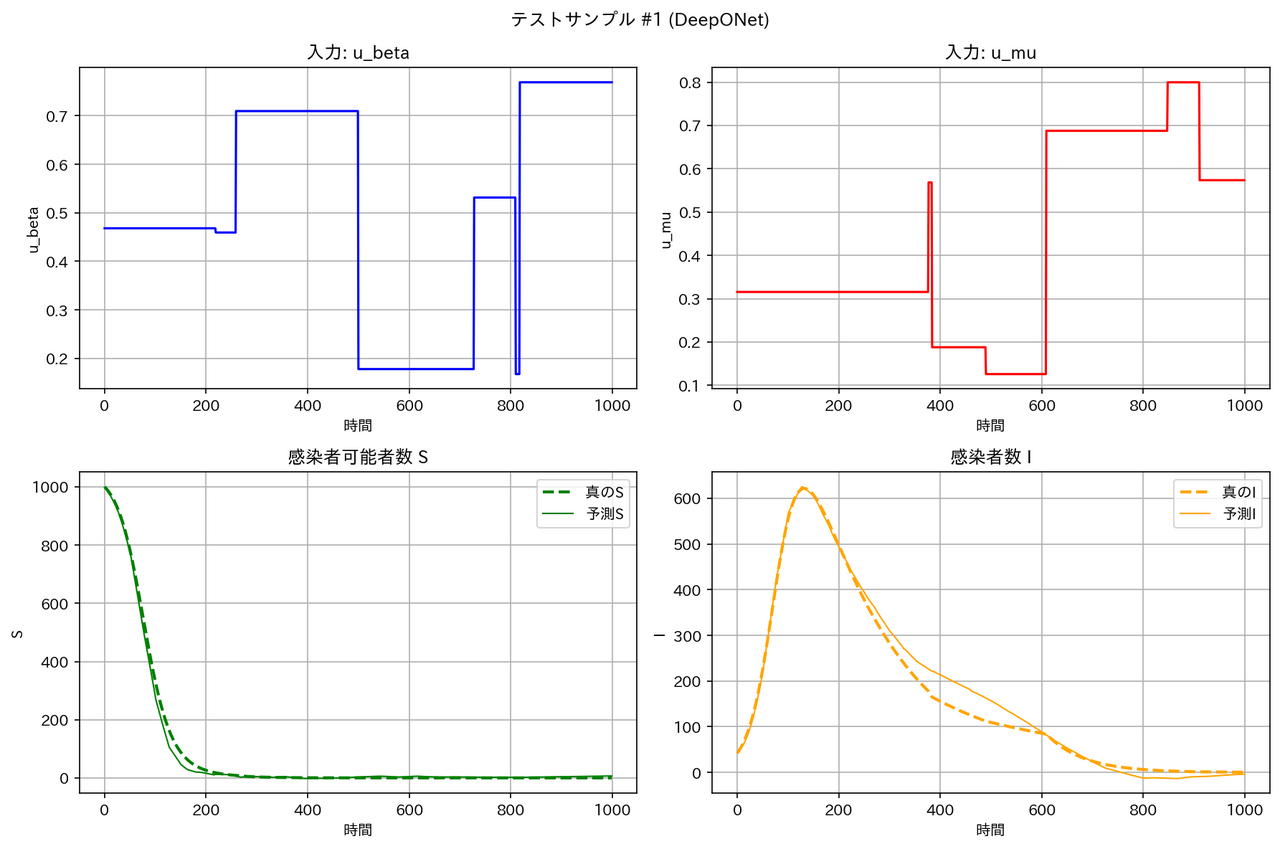 |
| FNO | 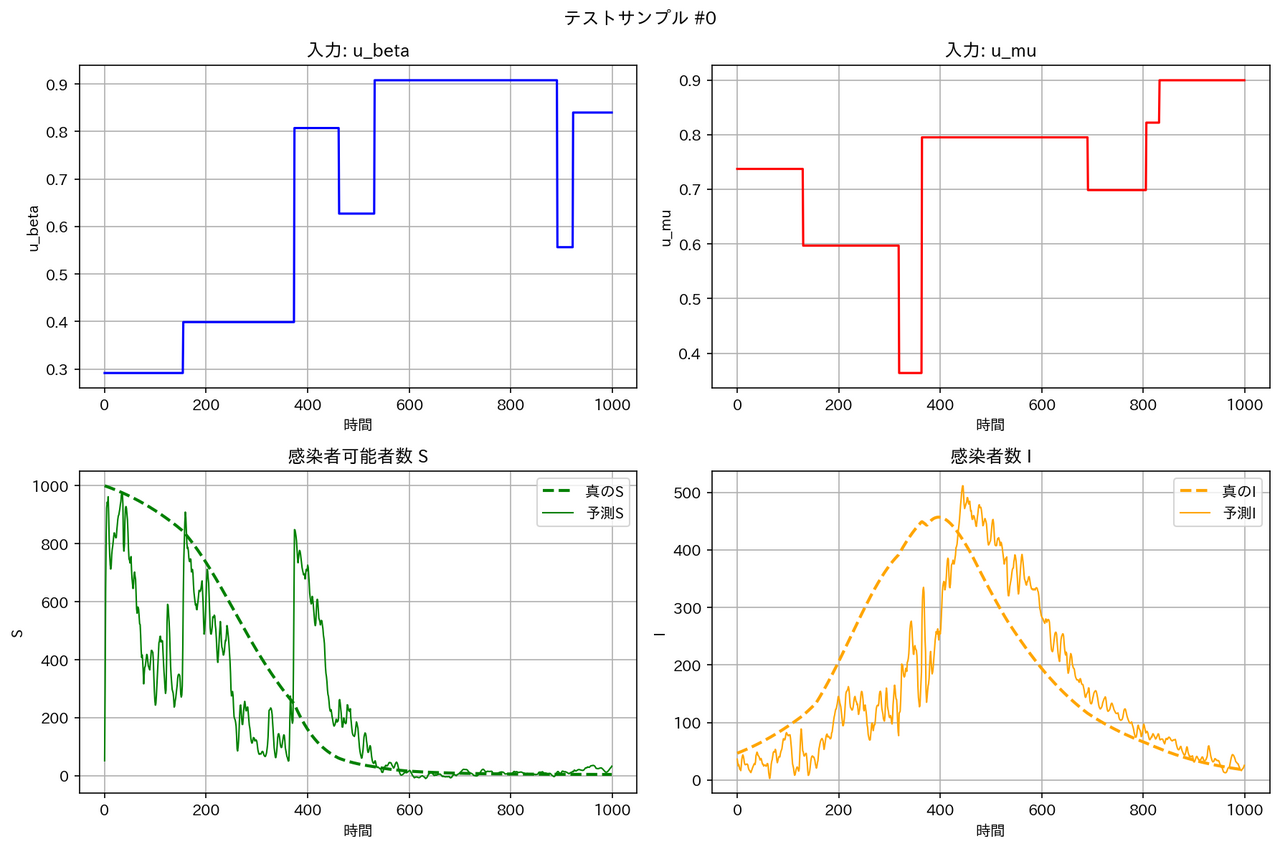 |
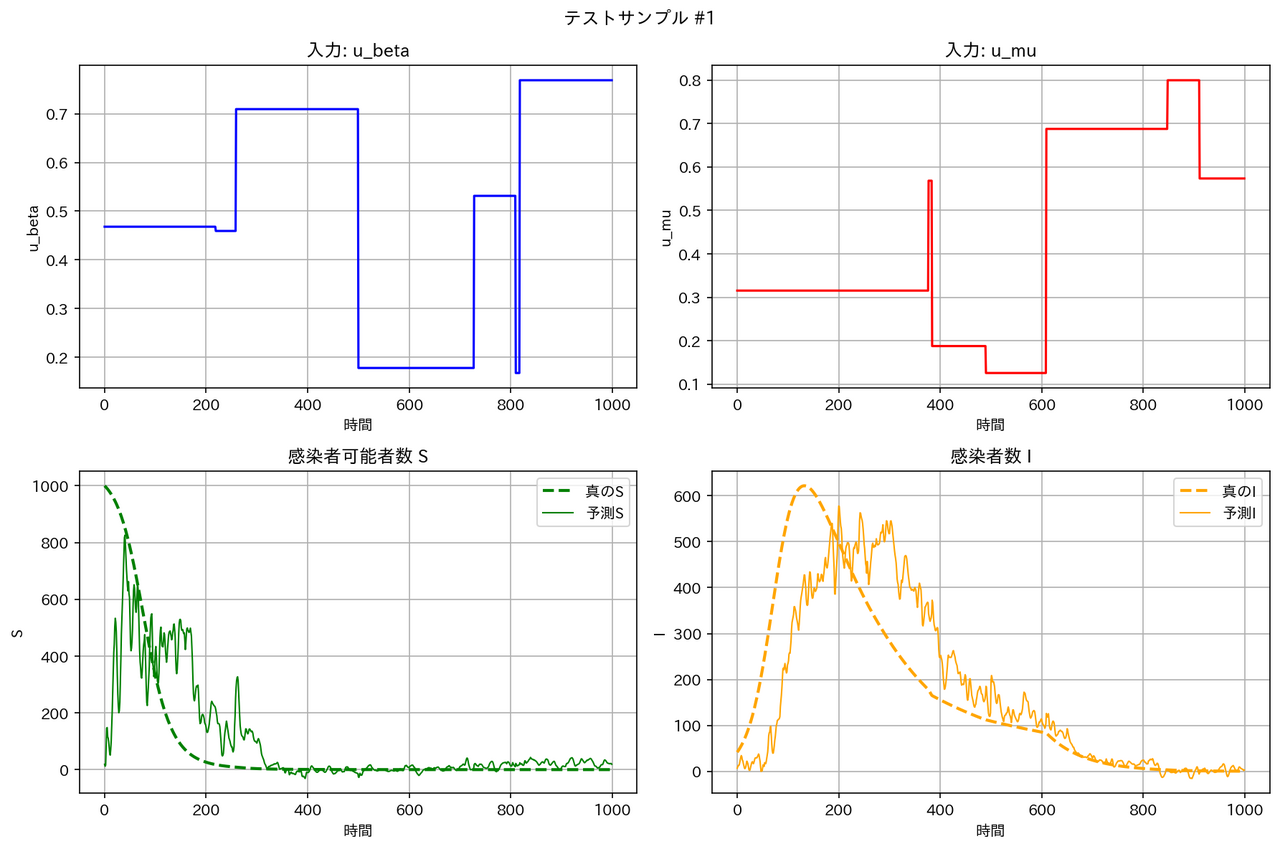 |
| WNO | 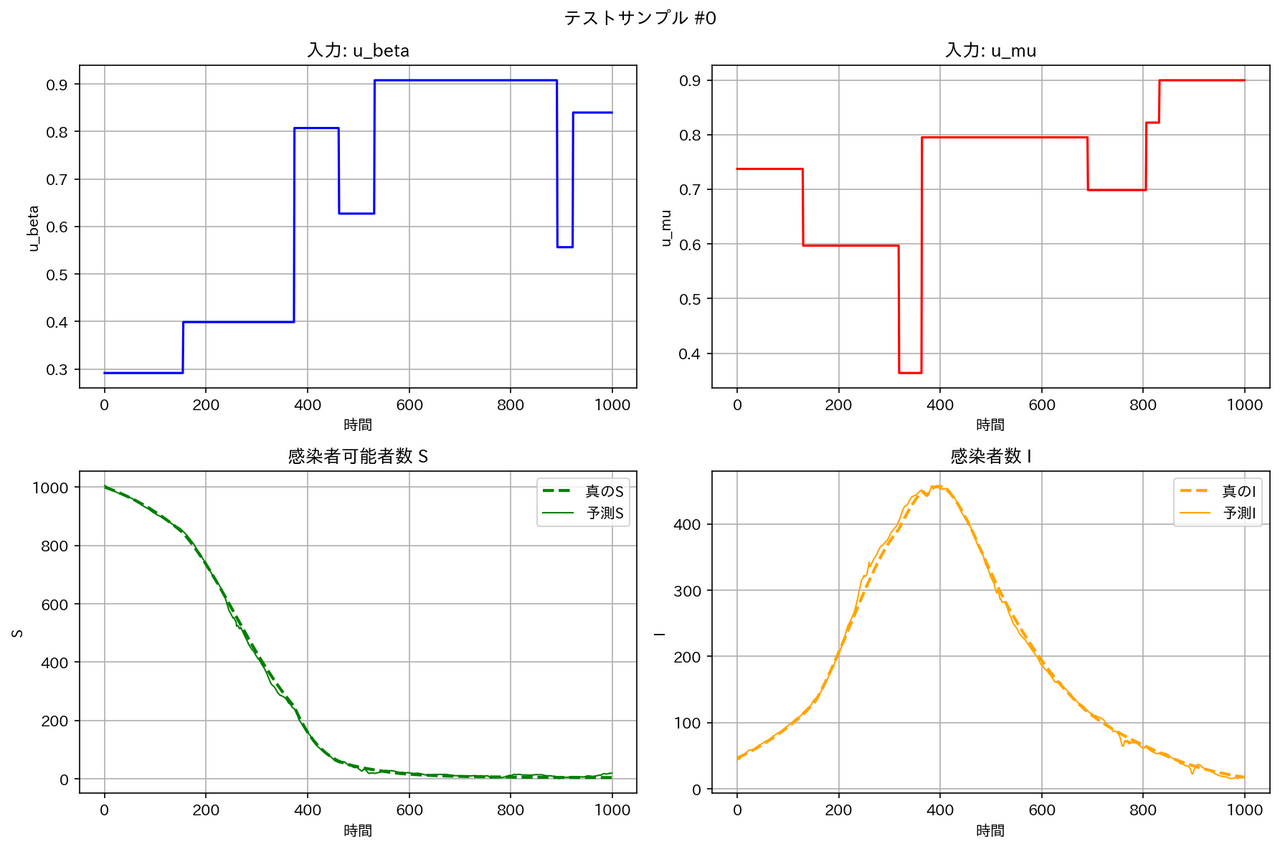 |
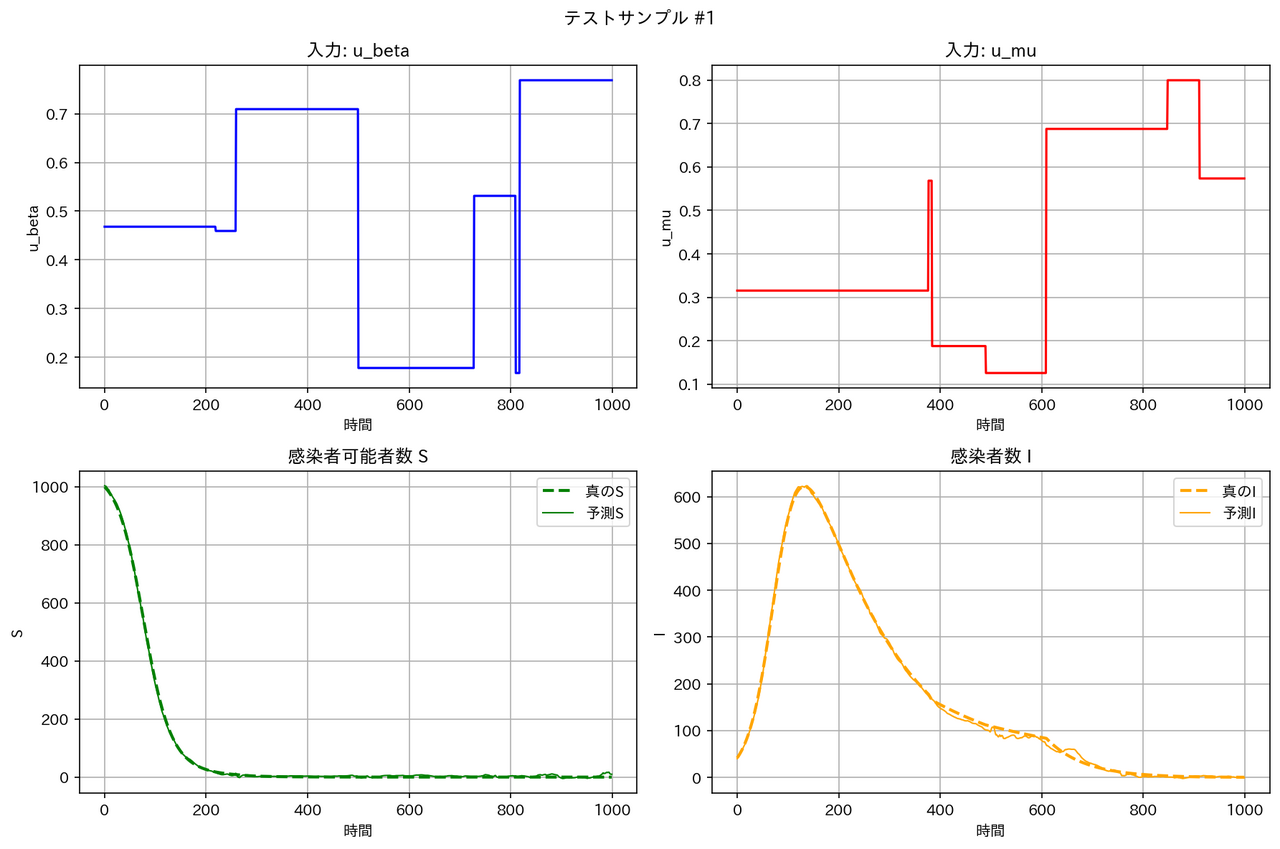 |
まとめ
本記事では、演算子学習による代理ソルバー作成についてご紹介しました。演算子学習のアイデアを説明したのち、代表的なアーキテクチャとして DeepGreen 、 DeepONet 、Neural Operator を紹介し、後者 2 つの手法については簡単な数値実験を行いました。
演算子学習は、流体力学等のシミュレーションで、CNN 等の通常のアーキテクチャによるモデルよりも高い性能を示すことが報告されています。また、演算子学習では学習時のデータの解像度と推論時のデータの解像度を変えることが出来るので、低解像度のデータで学習したモデルを高解像度での推論に用いる応用(zero-shot superresolution)も追求されています。これに関連して、低解像度での教師データの loss と高解像度での physics-informed loss (物理法則を満たさないことに対する罰則) を組み合わせた Physics-informed Neural Operator (PINO) は高い zero-shot superresolution 性能を示すことが報告されています [10]。また、学習データの生成コストを減らすために、Neural Operator を教師なしに事前学習し、in-context learning によって求解するアプローチも研究されています [11]。
このように、演算子学習を用いた代理ソルバーの作成は、まだ実用化にまでは至っていないにせよ、注目度の高い研究テーマとなっています。次回の記事では PINN の新しい解法として FrozenPINN をご紹介する予定です。
参考文献
- Neural operators for accelerating scientific simulations and design
- 「ニューラル作用素学習」『プラズマ・核融合学会誌』第102巻3号
- A Mathematical Analysis of Neural Operator Behaviors
- DeepGreen: deep learning of Green's functions for nonlinear boundary value problems
- Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
- Neural operator: Learning maps between function spaces with applications to pdes
- Fourier neural operator for parametric partial differential equations
- Wavelet neural operator for solving parametric partial differential equations
- Gnot: A general neural operator transformer for operator learning
- Physics-Informed Neural Operator for Learning Partial Differential Equations
- Data-Efficient Operator Learning via Unsupervised Pretraining and In-Context Learning


- PIML の概説 - 物理法則を組み込んだ深層学習技術(1)
- PINNの紹介 - 物理法則を組み込んだ深層学習技術(2)
- PINNの経路計画/動作計画問題への応用 - 物理法則を組み込んだ深層学習技術(3)
- PINNを用いた逆問題解析(逆解析)の解法 - 物理法則を組み込んだ深層学習技術(4)
- 光学メタマテリアルの設計への PIML の応用 - 物理法則を組み込んだ深層学習技術 (5)
- 演算子学習(作用素学習)による代理ソルバー作成 - 物理法則を組み込んだ深層学習技術 (6)









