- HOME
- psim言語講座(第19回)チュートリアル編(10) 強化学習AGV方式

更新日:2026年4月30日 15:49
公開日:2025年8月25日 13:27
本記事は当社が発行しているシミュレーションメールマガジンVol. 19の記事です。
シミュレーションメールマガジンの詳細・購読申込はこちら
のサポートページから
前回は、動的スケジューリング方式を導入し、製品の優先度と工程順序を考慮したAGVスケジューリングシステムを実装しました。
今回は、さらに高度な「強化学習AGV」方式を導入し、学習によって環境に適応するスケジューリングシステムを実装します。この方式では、ニューラルネットワークを用いたQ学習によってAGVの意思決定モデルを学習させ、複雑な状況に対応できる柔軟なシステムを構築します。
強化学習によるAGV制御
前回までの方式(ルールベース方式、動的スケジューリング方式)では、あらかじめ定められたルールに基づいて製品の優先順位を決定していました。これらの方式は単純で理解しやすいものの、環境の複雑さや変化に対して柔軟に対応することが難しいという制約があります。
強化学習方式では、AGVが「環境から学習する」能力を持ち、試行錯誤を通じて最適な行動を見つけ出します。具体的には以下のような特徴があります:
- 適応性: 動的に変化する環境に対して、継続的に学習して適応します。
- 経験からの学習: 過去の経験(成功と失敗)から学習し、徐々に行動を改善します。
- 長期的報酬の最大化: 短期的な利益だけでなく、長期的な性能向上につながる行動を学習します。
Q学習とニューラルネットワーク
今回のシステムでは、Q学習(Q-Learning)とニューラルネットワークを組み合わせたディープQ学習(Deep Q-Learning)を採用しています。Q学習は「状態(State)」と「行動(Action)」のペアに対する価値(Q値)を学習し、各状態において最適な行動を選択するための手法です。
ニューラルネットワークを使用することで、大規模かつ連続的な状態空間を扱うことができ、より複雑な環境でも効率的に学習が可能になります。
実装の詳細
QNetworkモデル
強化学習の中核となるQNetworkモデルは、ニューラルネットワークを用いて実装されています:
class QNetwork(nn.Module):
def __init__(self, input_size=5, hidden_size=5, output_size=1):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.fc3 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
このネットワークは5つの入力特徴量(状態の表現)を受け取り、1つの出力(行動の価値)を生成します。隠れ層は5ユニットで構成され、活性化関数にはReLU(Rectified Linear Unit)を使用しています。
状態表現
強化学習において、環境の状態をどのように表現するかは非常に重要です。今回のシステムでは、以下の5つの特徴量を用いて状態を表現しています:
- 移動時間(travel_time): 現在位置から次の工程までの移動時間
- 混雑度(congestion): 次の工程の混雑状況(キュー長と待ち時間から算出)
- 納期までの時間(time_to_due): 製品の納期までの残り時間
- 残り工程数(remaining_processes): 製品の完了までに必要な残りの工程数
- 優先度(priority): 製品に設定された優先度
def get_state_features(self, prod, current_loc, process_states, now):
if prod is None:
return None
# 工程までの移動時間
next_loc = prod.instructions[0] if prod.instructions else 3
travel_time = travel_matrix[current_loc][next_loc]
# 次の工程の混雑度
congestion = 0
if next_loc in [1, 2]:
congestion = process_states[next_loc].get_congestion_score()
# 納期までの時間
time_to_due = max(0, prod.due_date - now)
# 残りの工程数
remaining_processes = len(prod.instructions)
# 優先度
priority = prod.priority
return [travel_time, congestion, time_to_due, remaining_processes, priority]
これらの特徴量を組み合わせることで、AGVが直面する状況を数値的に表現し、学習アルゴリズムに入力することができます。
報酬設計
強化学習において、報酬の設計は学習の方向性を決定する重要な要素です。本システムでは、以下のような報酬体系を採用しています:
- 工程配置の成功: 製品を工程1または工程2に正しく配置した場合、基本報酬として10.0を付与
- 納期遵守のボーナス: 製品が納期内に完了した場合、最大50.0の報酬(納期より早いほど高い)
- 納期遅延のペナルティ: 納期を超過した場合、遅延の度合いに応じて報酬が減少(最大20.0から最小0.0)
# 工程配置成功の報酬
reward = 10.0
# 納期遵守の場合
if prod.completion_time <= prod.due_date:
time_bonus = 1 + (prod.due_date - prod.completion_time) * 0.1
reward = 50.0 * time_bonus
else:
# 納期遅延の場合
time_penalty = 1 - min(1.0, (prod.completion_time - prod.due_date) * 0.01)
reward = 20.0 * time_penalty
この報酬体系により、AGVは納期を守ることの重要性を学習し、特に納期が迫っている製品や遅延リスクの高い製品を優先的に処理するように行動を調整します。
探索と活用のバランス
強化学習において、「探索(Exploration)」と「活用(Exploitation)」のバランスは重要な課題です。本システムではε-greedy方式を採用し、学習初期は多くのランダム行動を行い(探索)、徐々に学習したモデルに基づく最適行動(活用)の割合を増やしていきます。
def select_best_product(self, candidates, current_loc, process_states, now):
if not candidates:
return None
# ε-greedy戦略
if random.random() < self.epsilon:
# ランダムに選択(探索)
return random.choice(candidates)
else:
# Qネットワークで評価して最適な製品を選択(活用)
best_score = float('-inf')
best_product = None
for prod in candidates:
state = self.get_state_features(prod, current_loc, process_states, now)
score = self.predict(state)
if score > best_score:
best_score = score
best_product = prod
return best_product
εの値は学習が進むにつれて徐々に減少し(epsilon_decay)、初期値の1.0から最小値0.01まで減少していきます。これにより、学習初期はさまざまな行動を試し、学習が進むにつれて最適と判断される行動を選択する確率が高くなります。
経験リプレイ
ニューラルネットワークを用いた強化学習では、学習の安定性を高めるために「経験リプレイ」という手法を採用しています。これは、過去の経験(状態、行動、報酬、次の状態)をメモリに保存し、ランダムにサンプリングして学習に使用する方法です。
# メモリに追加
self.memory.append((state, reward, next_state, done))
# メモリサイズ制限
if len(self.memory) > self.max_memory_size:
self.memory.pop(0)
# ミニバッチの作成
batch = random.sample(self.memory, self.batch_size)
この手法により、データ間の相関を減らし、より効率的かつ安定した学習が可能になります。
モデルの保存と読み込み
学習したモデルはファイルに保存することができ、後で再利用することが可能です。この機能により、学習済みのモデルを使って即座にシミュレーションを実行したり、さらなる学習のベースとして使用したりすることができます。
def save_model(self, path):
"""モデルを保存する"""
try:
self.model.save(path)
print(f"モデルを保存しました: {path}")
return True
except Exception as e:
print(f"モデル保存エラー: {e}")
return False
def load_model(self, path):
"""モデルを読み込む"""
try:
self.model.load(path)
self.target_model.load_state_dict(self.model.state_dict())
print(f"モデルを読み込みました: {path}")
return True
except Exception as e:
print(f"モデル読み込みエラー: {e}")
return False
強化学習AGVの実装
AGV実装(rl_agv関数)
強化学習を用いたAGVの実装は以下のようになります:
def rl_agv(agvname):
prod = None
current_loc = T0_LOC
last_state = None
while True:
# 製品を持っていない場合、強化学習で最適な製品を取得する
if prod is None:
lock = (yield getlock.request(name="lock"))["lock"]
candidates = []
candidates.extend(t0.buffer)
candidates.extend(t1.buffer)
candidates.extend(t2.buffer)
if candidates:
# 強化学習モデルで最適な製品を選択
prod = rl_model.select_best_product(candidates, current_loc, process_states, now())
# 選択した製品を取得
if prod in t0.buffer:
prod = (yield t0.get1(lambda v: v is prod, name="get"))["get"]
if prod.start_time is None:
prod.start_time = now()
elif prod in t1.buffer:
prod = (yield t1.get1(lambda v: v is prod, name="get"))["get"]
elif prod in t2.buffer:
prod = (yield t2.get1(lambda v: v is prod, name="get"))["get"]
# 現在の状態を記録
last_state = rl_model.get_state_features(prod, current_loc, process_states, now())
print(f"時間 {now()} {agvname} 製品選択 {prod.name} 状態: {last_state}")
lock.release()
# 製品を持っている場合、次の工程に配置
if prod is not None:
# 次の工程を決定(常にinstructionsの順番通りに処理)
if not prod.instructions:
# 残りの工程がない場合は工程3へ
next_loc = T3_LOC
else:
# 常に指示の順番通りに処理
next_loc = prod.instructions[0]
if next_loc is not None:
# 移動が必要な場合
if current_loc != next_loc:
move_time = travel_matrix[current_loc][next_loc]
print(f"時間 {now()} {agvname} 移動 {prod.name} 工程{current_loc} -> 工程{next_loc} 移動時間 {move_time} 残り工程: {prod.instructions}")
yield pause(move_time)
current_loc = next_loc
# 工程1または2の場合、対応するバッファへ配置
if next_loc in [1, 2]:
# 工程の指示から削除
prod.instructions.remove(next_loc)
# 工程の状態を更新(キュー長増加)
process_states[next_loc].queue_length += 1
process_states[next_loc].update(now())
print(f"時間 {now()} {agvname} 配置待ち {prod.name} 工程{current_loc} 納期 {prod.due_date} 残り工程: {prod.instructions}")
s = [None, s1, s2, None][next_loc]
yield s.put1(prod, name="put")
print(f"時間 {now()} {agvname} 配置完了 {prod.name} 工程{current_loc} 納期 {prod.due_date} 残り工程: {prod.instructions}")
# 報酬の計算と学習
reward = 10.0 # 工程配置成功の報酬
# 次の状態(製品がなくなるのでダミー状態)
next_state = [0, 0, 0, 0, 0]
# 学習
if last_state:
rl_model.learn(last_state, reward, next_state, False)
prod = None
# 工程3(最終工程)の場合、完了処理
elif next_loc == 3:
# 工程の指示から削除(リストに含まれている場合のみ)
if next_loc in prod.instructions:
prod.instructions.remove(next_loc)
prod.completion_time = now()
# 納期遵守の報酬計算
if prod.completion_time <= prod.due_date:
time_bonus = 1 + (prod.due_date - prod.completion_time) * 0.1
reward = 50.0 * time_bonus # 納期遵守ボーナス付き報酬
else:
time_penalty = 1 - min(1.0, (prod.completion_time - prod.due_date) * 0.01)
reward = 20.0 * time_penalty # 納期遅れペナルティ付き報酬
# 次の状態(製品がなくなるのでダミー状態)
next_state = [0, 0, 0, 0, 0]
# 学習
if last_state:
rl_model.learn(last_state, reward, next_state, True)
completed_products.append({
"name": prod.name,
"completion_time": prod.completion_time,
"due_date": prod.due_date
})
print(f"時間 {now()} {agvname} 製品 {prod.name} 完了 (工程3) 完了時間: {prod.completion_time} 報酬: {reward:.2f}")
prod = None
yield pause(1)
この実装では、従来の方式と同様に工程順序(instructions)は厳密に守られますが、製品の選択は強化学習モデルによって行われます。また、各行動(製品の配置や完了)に対して報酬が計算され、モデルの学習に使用されます。
トレーニングプロセス
強化学習モデルのトレーニングは、複数回のシミュレーションを通じて行われます。各反復では、以下のステップが実行されます:
- データセットの準備(製品情報の生成)
- シミュレーションの実行と経験の収集
- 経験リプレイによるモデルの更新
- パフォーマンス指標の計算と記録
- εの減衰(探索率の調整)
for iteration in range(training_iterations):
print(f"\nトレーニング反復 {iteration+1}/{training_iterations}")
# 各反復で製品のコピーを使用
training_products = [product.copy() for product in products]
# シミュレーション実行
completed_products, sim_time = run_simulation(training_products, agv_count, rl_model)
# パフォーマンス指標の計算と表示
# ...
トレーニングが完了すると、学習したモデルはファイルに保存され、後続のシミュレーションで使用することができます。
ベンチマーク結果
強化学習AGV方式を他の3つの方式(固定経路方式、ルールベース方式、動的スケジューリング方式)と比較してみます。結果は以下の指標で評価しています:
- 平均完了時間: 製品の生産開始から完了までの平均時間
- 平均遅延時間: 納期を超過した場合の平均遅延時間
- 最大遅延時間: 納期を超過した場合の最大遅延時間
- 納期遵守率: 納期内に完了した製品の割合
強化学習AGV方式の特徴として、以下のような点が挙げられます:
適応性と柔軟性
強化学習AGV方式は、さまざまな状況に対して適応的に行動を変化させることができます。特に:
- 混雑度の考慮: 工程の混雑状況を学習し、空いている工程を優先的に利用する傾向があります。
- 納期と優先度のバランス: 納期が迫った製品を優先しつつも、全体の効率を考慮した意思決定ができます。
- 長期的最適化: 即時の報酬だけでなく、将来的な報酬も考慮した意思決定ができます。
学習曲線
強化学習モデルは、トレーニング回数が増えるにつれてパフォーマンスが向上します。初期段階では他の方式に劣る場合もありますが、十分な学習を経ると、他の方式と同等かそれ以上のパフォーマンスを示すようになります。
シミュレーション結果の分析
複数のデータセットでのシミュレーション結果を分析すると、強化学習AGV方式は以下のような特性を示しています:
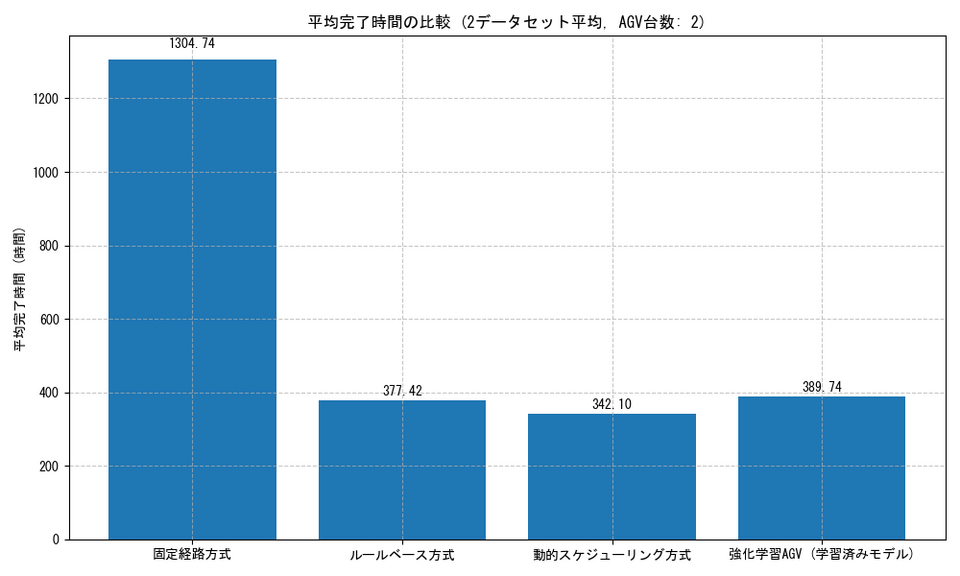
平均完了時間
学習を重ねたモデルでは、ルールベース方式と同等かやや遅い平均完了時間を示しています。
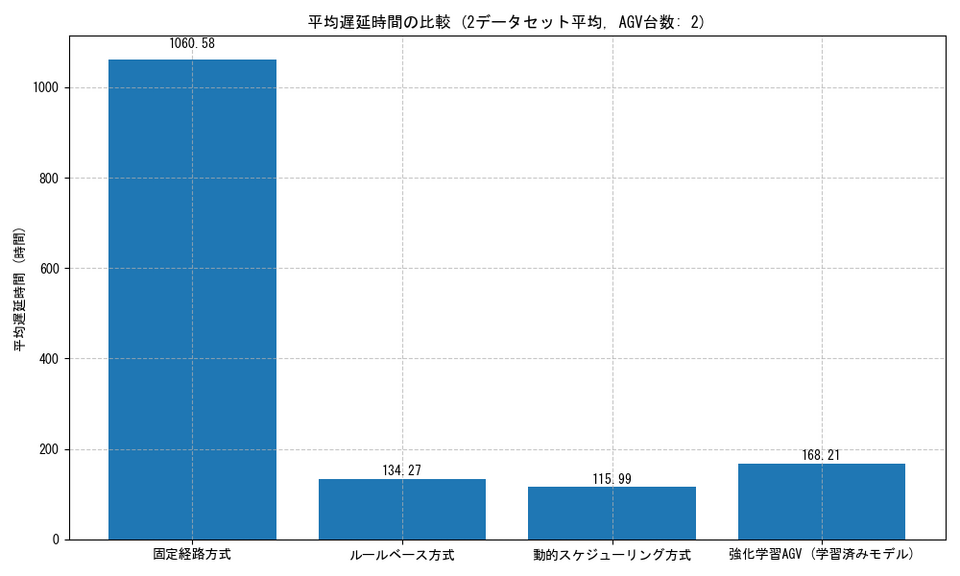
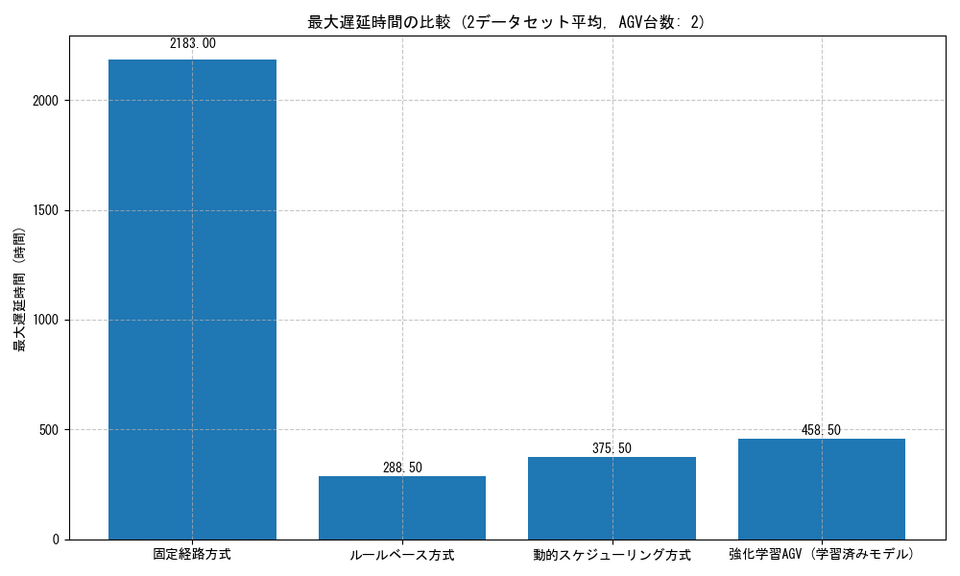
平均・最大遅延時間
強化学習AGV方式は平均遅延時間、最大遅延時間は他の方式に劣る場合があります。これは、極端に遅延するリスクの高い製品を特に優先するよう学習した結果と考えられます。
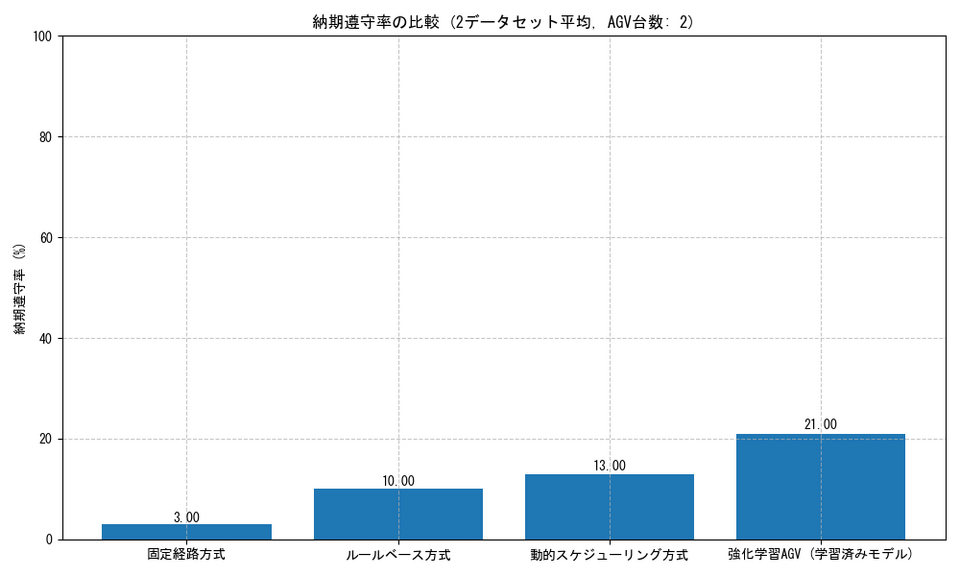
納期遵守率
納期遵守率に関しては、報酬設計において納期遵守に高い重みを置いているため、高い値となっています。
強化学習AGVの長所と短所
長所
- 適応性: 環境の変化や異なるデータセットに対して適応的に行動を調整できます。
- 複雑な意思決定: 多数の要素を考慮した複雑な意思決定が可能です。
- 継続的な改善: 運用を続けるほど学習が進み、パフォーマンスが向上します。
- 自己最適化: 人間の介入なしに自己最適化する能力を持ちます。
短所
- 学習コスト: 十分なパフォーマンスを得るには、相当量のトレーニングが必要です。
- 解釈性の不足: ニューラルネットワークの判断根拠が「ブラックボックス」となり、理解や検証が難しい場合があります。
- 過学習のリスク: 特定の環境に過度に適応し、未知の状況での汎化性能が低下する可能性があります。
- 実装の複雑さ: 他の方式と比較して、実装が複雑で専門知識が必要です。
まとめ
今回は強化学習を用いたAGV制御方式を導入し、環境に適応して学習する柔軟なスケジューリングシステムを実装しました。
この方式の主な特徴は以下の通りです:
- ニューラルネットワークによるQ学習: 複雑な状態空間を扱い、最適な行動を学習します。
- 経験リプレイによる安定した学習: 過去の経験を再利用することで、効率的かつ安定した学習を実現します。
- 報酬設計による行動の方向付け: 納期遵守に大きな報酬を設定することで、重要な目標に向けた行動を促進します。
- 探索と活用のバランス: ε-greedy戦略により、新しい行動の探索と学習した知識の活用をバランス良く行います。
強化学習AGV方式は、単純なルールベース方式と比較すると実装が複雑で、十分なパフォーマンスを得るまでに学習時間が必要ですが、複雑な環境や変化する条件に対して高い適応性を持ち、継続的に改善していく能力があります。
実際の生産現場では、この学習能力を活かすことで、日々変化する生産条件や予期せぬ状況に柔軟に対応できるシステムを構築することができるでしょう。また、強化学習の枠組みは、今回のAGV制御だけでなく、生産計画、在庫管理、品質管理など、さまざまな領域に適用可能です。
将来的な発展として、より複雑な状態表現(例えば、全AGVの位置情報やシステム全体の状態)や、より洗練された報酬設計(例えば、省エネルギーやメンテナンスコストの考慮)を取り入れることで、さらに高度な意思決定が可能になるはずです。


- psim言語講座(第1回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を書いてみる
- psim言語講座(第2回)離散イベントシミュレーション(待ち行列 M/M/1モデル)を読んでみる
- psim言語講座(第3回)待ち行列 M/M/1 シミュレーションを拡張してみる
- psim言語講座(第4回)生産ラインシミュレーションを書いてみる
- psim言語講座(第5回)psimとexcelを連携してみる
- psim言語講座(第6回)psimとexcelを連携してみる(グラフ編)
- psim言語講座(第7回)連続型シミュレーションを書いてみる
- psim言語講座(第8回)エージェントシミュレーションを書いてみる
- psim言語講座(第9回)エージェントシミュレーションを拡張してみる
- psim言語講座(第10回)チュートリアル編(1)psim で 「Hello World!」
- psim言語講座(第11回)チュートリアル編(2)psim のプロセスを使いこなす
- psim言語講座(第12回)チュートリアル編(3)psim のファシリティを使いこなす
- psim言語講座(第13回)チュートリアル編(4)psim のストアを使いこなす
- psim言語講座(第14回)チュートリアル編(5)psim のスケジューラを使いこなす
- psim言語講座(第15回)チュートリアル編(6)(続)psim のストアを使いこなす
- psim言語講座(第16回)チュートリアル編(7)(続)psim のストアを使いこなす
- psim言語講座(第17回)チュートリアル編(8) AGV による搬送
- psim言語講座(第18回)チュートリアル編(9) 動的スケジューリング方式
- psim言語講座(第19回)チュートリアル編(10) 強化学習AGV方式







