- HOME
- S4で始める強化学習(第11回)在庫管理問題で作ってみる(3/3)

更新日:2026年4月30日 15:48
公開日:2024年12月20日 16:19
本記事は当社が発行しているシミュレーションメールマガジンVol. 16の記事です。 シミュレーションメールマガジンの詳細・購読申込はこちらのサポートページから
はじめに
S4 で強化学習を使ったシミュレーションモデルを作成してみようという講座の11回目の記事になります。 第8回でご紹介した在庫管理問題のシミュレーションモデルの作成について、3回に分けてご紹介していきます。最初の2回では在庫管理問題のモデルの組み立て、最後の1回で強化学習モデルの組み込みを行う予定です。今回は強化学習モデルの組み込み部分になります。 前回の記事をご覧になっていない方はS4 で始める強化学習(第10回)在庫管理問題で作ってみる(2/3)をご覧ください。 ※前回までのモデルに一部修正が入っています。前回までのモデルの修正後のプロジェクトはこちらからダウンロードいただけます。
実装の方針
今回のモデルの実装は次のように4段階に分けて行いました。
- 在庫消費フローの実装
- 在庫補充フローの実装
- 強化学習モデルの組み込み
- 強化学習結果の可視化
前回までで在庫管理問題のモデルを作成しました。今回は、強化学習モデルの組み込みと強化学習結果の可視化を行いたいと思います。 今回作るs4プロジェクトはこちらからダウンロードいただけます。
強化学習モデルの組み込み
強化学習部品の配置
今回は在庫補充時の発注数を強化学習を使って学習させたいと思います。 前回までに発注数をランダムに選ぶというモデルを作成していましたので、発注数の設定部分のみを入れ替えていきます。
まず、必要な部品を配置していきます。今回使う部品は以下の通りです。
| 部品名 | タブ | 説明 |
|---|---|---|
| 離散イベント用強化学習モデル | 学習モデル | 強化学習モデルを作成し、シミュレーションの中で使えるようにする。 |
| 強化学習設定 | 部品 | 入力されたアイテムの属性値に強化学習モデルを使って選択した行動の値を設定する。 今回は、強化学習の行動値である発注数をアイテム「注文」の属性に設定する。 |
| 即時報酬確定 | 部品 | 入力されたアイテムの属性に即時報酬を割り当てる。 今回であれば、強化学習を使って割り当てた発注数分注文したときに発生する分のコスト+在庫管理コストがかかる。 |
もともと配置していた「発注数設定」部品で行う動作は今回「強化学習設定」部品が代わりに行うため、削除しておきます。 以下のようなフローとなるように組み立てていきます。
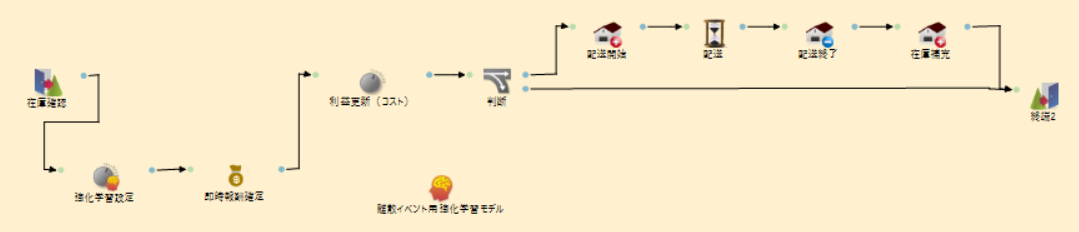
部品の編集
まずは強化学習設定部品の設定を行います。 強化学習設定部品の編集画面を開き、画像のように設定します。
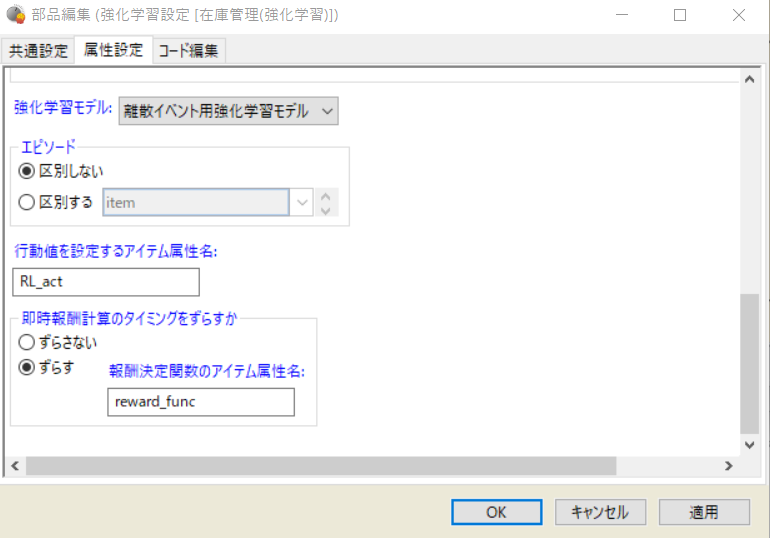
このように設定すると、アイテム「注文」の属性RL_actに、強化学習モデルで設定する行動値を割り付けることができます。今回この属性は発注数を表しており、この後の即時報酬の計算や利益計算、発注に用います。 また、今回は発注数を割り付けた後に発注数に応じて即時報酬値を決定したいため、「即時報酬計算のタイミングをずらす」というオプションを設定します。 報酬決定関数のアイテム属性名にはreward_funcを指定しておきます。即時報酬計算実行時にこの属性名を指定することで、予め指定しておいた報酬の計算を後から行うことができます。
次に即時報酬確定部品の設定を行いますが、ここでは報酬決定関数のアイテム属性名には、reward_funcを指定すればよいことになります。
強化学習モデルの編集
観測値の設定
最後に離散イベント用強化学習モデルの設定を行います。
今回の観測値を設定します。今回の強化学習では、観測値として「在庫数」と「到着待ち製品数」を設定するのでした。 状態数が大きくなりすぎないように、それぞれ(発注個数単位である)4で割った数を観測し、 在庫数については20個以上の製品数についてはすべて同じ状態として観測します。
まず、「観測値集合の次元」を設定します。 今回は2種類の観測値があるため、+ボタンから2種類の観測値を作成し、以下の図のように設定しておきます。
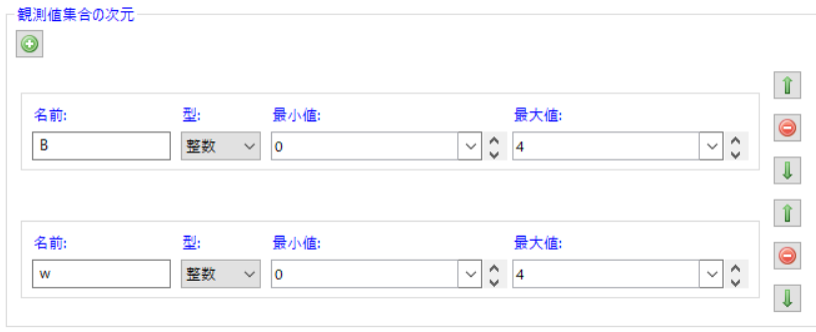
観測値Bを在庫数、観測値wを到着待ち製品数として利用します。
次に、「観測値計算関数」を設定します。観測値計算関数のコード編集画面を開き、以下のようにコード編集します。
def observation(self, simulator, agent): # 以下のコードを入力
B = int(simulator.rStore.sizeBuffer()/simulator.param.order_unit)
if B > 4:
B = 4
w = int(simulator.rStore3.sizeBuffer()/simulator.param.order_unit)
if w > 4:
w = 4
return {"B": B, "w": w}
ここで定義するメソッドobservationの返り値には、先ほど設定した観測値の名前をキーに持ち、観測値を値にもつ辞書を設定します。 今回のシミュレーションでは在庫のストア資源はrStoreというオブジェクト名で、配送中のストア資源はrStore3というオブジェクト名でした。それぞれ、ストア部品のsizeBufferメソッドで蓄えられている資源量が取得できますので、Bは在庫数を、wは配送中の到着待ち製品数をパラメータorder_unitで割ったものを取得していることになります。
行動の設定
今回、行動値には発注数を発注単位で指定します。行動の種類数に5と指定します。このようにすると行動値としては 0 - 5 の整数値のどれかが選ばれます。
即時報酬の設定
即時報酬としては、前日の売り上げ分から注文分のコストと在庫コストを差し引いたものを与えます。 即時報酬値計算関数のコード編集画面を開き、以下のようにコード編集します。
def reward(self, simulator, item, prev_time): # 以下のコードを入力
sales = simulator.rStore2.sizeBuffer() * simulator.param.price
cost = item.RL_act * simulator.param.order_unit * simulator.param.cost + simulator.rStore.sizeBuffer()*simulator.param.m_cost
return sales - cost
強化学習パラメータの設定
最後に、強化学習パラメータの設定を行います。 今回もQ学習を使って学習を行います。次の画像のように設定し、 各パラメータはパラメータパネルから設定できるようにしました。
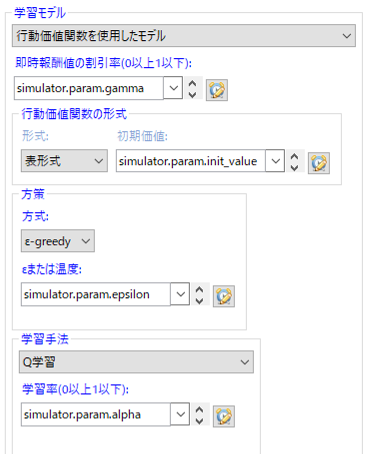
パラメータとしては、init_valur=800, epsilon = 0.001, alpha = 0.6, gamma = 0.99のように設定すると 累積利益が上がっていく様子を確認できるはずです。
前回まではシミュレーション時間を気にしていませんでしたが、あまり短いと効果がわかりませんので、 シミュレーション時間には10000程度かそれ以上に設定してください。
強化学習結果の可視化
第8回で説明したような強化学習結果の可視化は分析スクリプト機能を使って行います。 こちらのコードはpythonのライブラリpandas, numpy, matplotlibも用いて記述しています。 作成済みのモデルからコードをご確認ください。
おわりに
ここまでの設定で、強化学習が実行できるようになりました。
今回までで強化学習を組み込んだシミュレーションモデルの作成ができ、実行できるようになりました。 次回は今回のモデルの問題点とその改善方法やパラメータ設定についていくつか解説を行います。


- S4 で始める強化学習(第1回)離散イベントシミュレーションで使ってみる
- S4 で始める強化学習(第2回)離散イベントシミュレーションで作ってみる
- S4 で始める強化学習(第3回)離散イベントシミュレーションで理解を深める
- S4 で始める強化学習(第4回)エージェントシミュレーションで使ってみる
- S4 で始める強化学習(第5回)エージェントシミュレーションで作ってみる(1/2)
- S4 で始める強化学習(第6回)エージェントシミュレーションで作ってみる(2/2)
- S4 で始める強化学習(第7回)エージェントシミュレーションで理解を深める
- S4で始める強化学習(第8回)在庫管理問題で使ってみる
- S4で始める強化学習(第9回)在庫管理問題で作ってみる(1/3)
- S4で始める強化学習(第10回)在庫管理問題で作ってみる(2/3)
- S4で始める強化学習(第11回)在庫管理問題で作ってみる(3/3)
- S4で始める強化学習(第12回)在庫管理問題で理解を深める






