- HOME
- S4 で始める強化学習(第2回)離散イベントシミュレーションで作ってみる

更新日:2026年4月30日 15:43
公開日:2022年6月27日 17:02
本記事は当社が発行しているシミュレーションメールマガジンVol. 7の記事です。 シミュレーションメールマガジンの詳細・購読申込はこちら のサポートページから
はじめに
S4 で強化学習を使ったシミュレーションモデルを作成してみようという講座の2回目の記事になります。 1回目の記事をまだお読みでない方は、こちらからどうぞ。
前回、離散イベントシミュレーションで強化学習を使うミニマルなモデルとして「窓口の割り当て問題」を紹介し、S4 で実行する様子をお見せしました。 2回目の今回は、第1回で使用したモデルの S4 での作成手順から学習結果の確認方法までをご紹介します。
S4 での作成手順
S4 には強化学習を実装するためのひな形の部品が用意してあり、簡単な学習モデルであればそれを活用することで手軽に実装することができます。ここではシミュレーター部分は完成していたとして、そこに強化学習を組み込む過程をお見せします。
S4 をお持ちの方で作成手順を体験したい方は、こちらからプロジェクトファイルをダウンロードして、窓口の割り当て.s4というファイルをインポートしてください。
まず、左のブラウザから「離散イベント用強化学習モデル」を右のエディタへドラッグ&ドロップして、ひな形の部品を配置します。
次に強化学習の中身を設定します。基本的には次の3点を設定する必要があります。
- エージェントが何を観測するか
- エージェントがどのような行動を取るか
- エージェントに与える即時報酬
これらの設定をもとに、エージェントは「○○を観測したときに××の行動を取れば△△くらい報酬が得られるだろう」ということを学習して、観測をもとに報酬が最大になるような行動を取るようになります[1]。 以下で細かい設定内容を説明しますが、先に要点をお伝えすると「毎秒お客が来店するたびにエージェントは2つの窓口の行列の長さを観測し、どちらかの窓口に案内するという行動を取り、待機人数にマイナスをつけたものを即時報酬として受け取る」と設定しています。
まず、観測と行動について設定します。「離散イベント用強化学習モデル」をダブルクリックして開き、属性設定タブの「観測値集合の次元」で追加ボタンを2回押して、n1、n2 という名前の変数を定義します。それぞれ型は整数、最小値と最大値は0と3とします。またその下の「行動の種類数」を2とします。そして属性設定タブの「観測値計算関数」を開いて、次のコードを入力します。
ret = {"n1": 0, "n2": 0}
ret["n1"] = min(simulator.getTimeMonitor(u"窓口利用1-入力1")[u"バッファ"][-1], 3)
ret["n2"] = min(simulator.getTimeMonitor(u"窓口利用2-入力1")[u"バッファ"][-1], 3)
return ret
ここまでで2つの窓口利用のバッファ、つまり行列の長さをエージェントが観測し、2種類の行動を取ると設定できました。 簡単のため、行列の長さは3以上のとき値を3で丸めて、観測値が0から3の間に収まるようにしています。 simulator.getTimeMonitor(u"窓口利用1-入力1")[u"バッファ" ] という部分は、S4 の基盤であるpsim言語特有の書き方になっていますが、設定画面の右側の変数一覧からドラッグ&ドロップして入力できますのでご安心ください。 また、最後にシミュレーションのフローに本モデルを組み込む際に、2種類の行動がお客を窓口1と2のどちらに案内するかに対応するように、S4 の方で自動的に設定が行われます。
次に、即時報酬の設定をします。お客の平均通過時間を短くしたいという問題設定でしたが、例えば行列の長さの和にマイナスをつけたものを即時報酬とすることでこれを達成することができそうです。これはエージェントは報酬を最大化する、つまり行列の長さの和を最小化するような行動を取るようになるためです[2]。 属性設定タブの「即時報酬値計算関数」を開いて、次のコードを入力します。
return -(simulator.getTimeMonitor(u"窓口利用1-入力1")[u"バッファ"][-1] + \
simulator.getTimeMonitor(u"窓口利用2-入力1")[u"バッファ"][-1])
最後に、シミュレーションのフローに作成した強化学習モデルを組み込みます。 今回はこの強化学習モデルを窓口の割り当てに利用したいので、お客のフローの分岐点にあたる「来店の記録」にこのモデルを設定します。 「来店の記録」をダブルクリックして開き、共通設定タブの下の方にある出力ポートの選択方式を 「強化学習」に、また強化学習モデルを先ほどの「離散イベント用強化学習モデル」に設定します。
設定は以上です。メニューからモデルを開始するボタンを押すと、前回の記事でお見せしたものと同様の結果が得られるかと思います。
- 本記事では微妙な使い分けとして、即時報酬の長期的な総和を報酬と呼んでいます。詳しくは3回目の記事をお読みください。
- 行列の長さの和の期待値の最小化と、平均通過時間の最小化が一致するかは自明ではありませんが、定常状態においては一致します。横軸に時間、縦軸に人数を取って、平均的な来店人数と退店人数の直線を書くと、どちらも間に挟まれた領域の最小化に対応するためです。
学習結果の確認
シミュレーションを実行したら、学習結果を確認してみましょう。 左のブラウザのワークスペースから、「窓口の割り当て」プロジェクトの出力以下にある「離散イベント用強化学習モデル - 学習モデル」を右クリックし「学習モデルを閲覧する」を選択します。 設定タブ下の方の計算ボタンを押すと、エージェントが学習によって獲得した行動価値関数が表示されます。これは最初に述べた「○○を観測したときに××の行動を取れば△△くらい報酬が得られるだろう」を表す表です。表の観測値が○○、行動値が××、値が△△に対応し、行動値の0、1はそれぞれ窓口1、2への案内を表します。
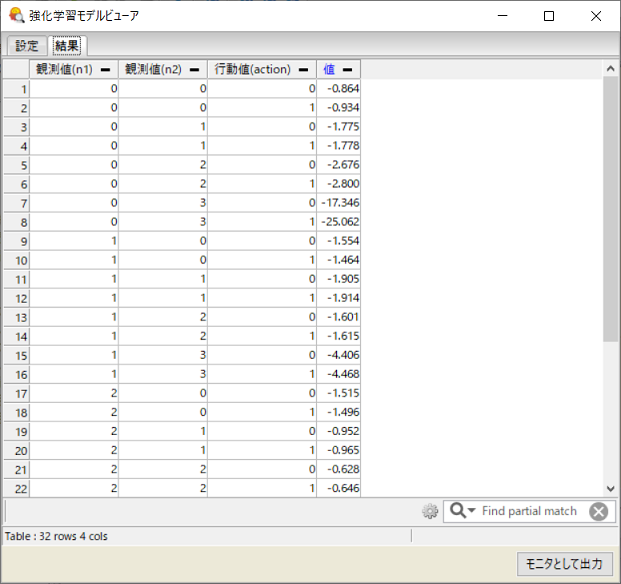
これを見ると基本的に、観測値 n1 と n2 のどちらかが小さいときは、対応する窓口に案内する方が値が高いという直観的に正しい結果が得られていることがわかります。 また観測値 n1 と n2 が同じ値のときは、窓口1に案内する方が値が高くなっています。これは窓口1の方が利用時間が短いことを学習によって取得できていることを意味します。
表の値という列は、おおまかには即時報酬の期待値、つまり行列の長さの和にマイナスをつけたものの期待値に比例する値になっています。観測値 n1 または n2 が3以上のとき値がかなり小さくなっていますが、これは観測値を3で丸めている影響であり、観測値が4以上のときの結果も含んでいます。 また観測値 n1、n2 が0、3のところの値が飛び抜けて小さいですが、これは最初に行列が膨れ上がったとき以降このような状況になっておらず(前回の記事の図を参照)、その時点で表の更新が止まっているためであると考えられます。 このように経験数の少ない状況における値は、必ずしも正確ではないことに注意してください。
今回までで、窓口の割り当て問題の基本的な性質から S4 で実装するところまで解説しました。 次回、強化学習のパラメータについて解説します。


- S4 で始める強化学習(第1回)離散イベントシミュレーションで使ってみる
- S4 で始める強化学習(第2回)離散イベントシミュレーションで作ってみる
- S4 で始める強化学習(第3回)離散イベントシミュレーションで理解を深める
- S4 で始める強化学習(第4回)エージェントシミュレーションで使ってみる
- S4 で始める強化学習(第5回)エージェントシミュレーションで作ってみる(1/2)
- S4 で始める強化学習(第6回)エージェントシミュレーションで作ってみる(2/2)
- S4 で始める強化学習(第7回)エージェントシミュレーションで理解を深める
- S4で始める強化学習(第8回)在庫管理問題で使ってみる
- S4で始める強化学習(第9回)在庫管理問題で作ってみる(1/3)
- S4で始める強化学習(第10回)在庫管理問題で作ってみる(2/3)
- S4で始める強化学習(第11回)在庫管理問題で作ってみる(3/3)
- S4で始める強化学習(第12回)在庫管理問題で理解を深める









