- HOME
- S4 で始める強化学習(第4回)エージェントシミュレーションで使ってみる

更新日:2026年4月30日 15:47
公開日:2023年1月16日 19:01
本記事は当社が発行しているシミュレーションメールマガジンVol. 9の記事です。 シミュレーションメールマガジンの詳細・購読申込はこちら のサポートページから
はじめに
S4 で強化学習を使ったシミュレーションモデルを作成してみようという講座の4回目の記事になります。
前回まで、離散イベントシミュレーションで強化学習を使う例として窓口の割り当て問題を取り上げ、一通り解説を行いました。今回からは話題を変えて、エージェントシミュレーションで強化学習を使う例を見ていきます。
崖歩き問題
エージェントシミュレーションで強化学習を使う簡単な例として、崖歩き問題[1]を考えます。次の図で表されるような格子グラフを環境とします。
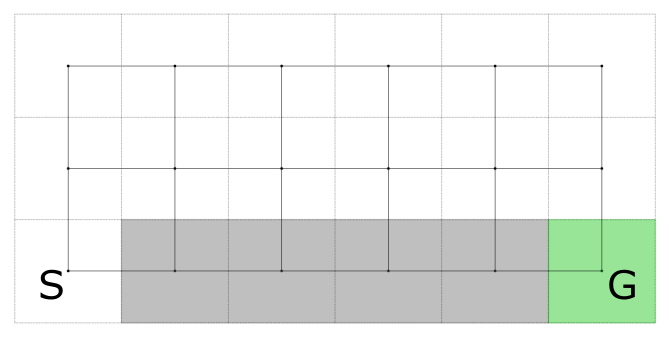
エージェントは左下のスタート地点(S)から出発し、毎時刻上下左右のどれかのマスに移動します。今回は予め決められた即時報酬があり、基本的には移動する度に -1 を即時報酬として獲得します。ただしスタート地点の右側の灰色領域は崖を表しており、これらのマスに移動すると -100 を即時報酬として与えられ、さらにスタート地点に戻されてしまいます。右下のゴール地点に移動すると +10 を即時報酬として獲得し、エージェントのタスクは終了となります。
スタートからゴールまでの即時報酬の和を最大化するような行動を学習することが目標です。窓口の割り当て問題との大きな違いとして、今回はエージェントのタスクに終わりがあります。スタートからゴールまでの期間をエピソードと言います。エージェントはエピソードを繰り返しながら、エピソード内での報酬を最大化するように行動を学習します。
- この問題は、R. Sutton and A. Barto, Reinforcement Learning, Second Edition: An Introduction (The MIT Press, 2018) の例 6.6 を参照しました。
S4 で実行
このモデルを S4 で実装した例をこちらからダウンロードできます。S4 をお持ちの方は、S4 の画面上にドラッグ&ドロップして、プロジェクトをインポートしてみてください。
※ S4 のversion 6.3をご利用の方は修正パッチが出ていますので、こちらから修正パッチをダウンロードして実行した後、プロジェクトを動かしてください。
モデルを開始すると、エージェントの行動がアニメーションとして確認できます。 行動の様子が確認できたらアニメーションを閉じて、最後までシミュレーションを実行してください。 シミュレーションの実行後、エピソードあたり報酬と書かれたアイコンをクリックすると、次のようなプロットを確認できます。
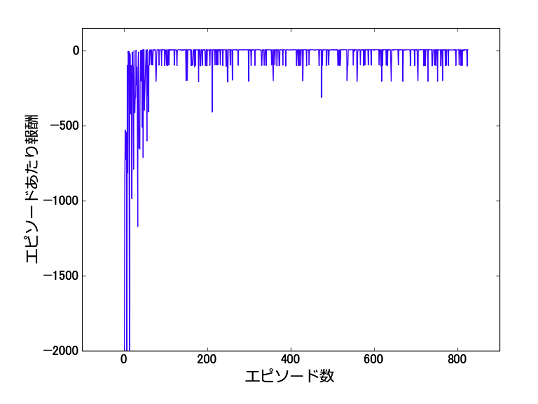
これはエピソードごとの報酬をプロットしたものです。 最初の頃は負に大きい値となっていますが、これは何度も崖に足を踏み入れてスタート地点に戻されているためです。 エピソードを重ねて学習が進むと、崖を避けながらゴール地点まで短い時間でたどり着けるようになり、0付近の報酬を獲得できるようになります。
本モデルでは、窓口の割り当て問題のときと同じくQ学習を学習手法として採用しています[2]。 $\varepsilon = 0.1$ と設定しているため、学習が進んだ後も一定の確率で崖に落ちてしまいます。 後半の下向きのスパイクはそうした事象を表していると考えられます。
それでは次に、学習によって得られた行動価値関数を確認してみましょう。 左のブラウザのワークスペースから、「崖歩き(強化学習)」プロジェクトの出力以下にある「エージェント用強化学習モデル - 学習モデル」を右クリックし「学習モデルを閲覧する」を選択します。 設定タブ下の方の計算ボタンを押すと、行動価値関数が表示されます。
今回はこれを可視化したいと思います。 結果タブ下の方の「モニタとして出力」ボタンを押して、モニタの名前を「行動価値」と設定します。 そしたら強化学習モデルビューアは閉じて、メインのエディタ上で右クリックを押し、分析スクリプトを開始するからvisActionValueを選択します。 すると以下のようなプロットが表示されるかと思います。
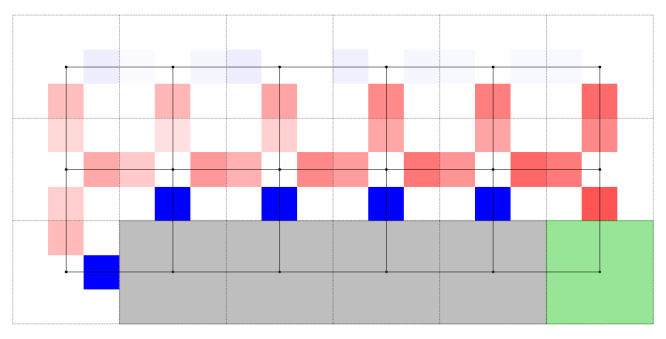
これは各マスにおける上下左右の行動の価値を色で表したものです。 赤は正の値、青は負の値を意味し、濃淡で絶対値の大きさを表しています。 行動価値関数の値は、その後の即時報酬の和の期待値[3]を表したものでした。 実際、崖に足を踏み入れるような行動は濃い青色として表示されています。 また崖に沿ってスタートからゴールまで真っすぐに進むのが、最適な行動として学習できていることが読み取れます。
環境の大きさはパラメータとして設定できるようにしました。メニューのモデルから「パラメータを編集する」を押して、パラメータタブから横幅と高さを設定できます。ぜひこれらのパラメータや強化学習のパラメータを変更して、色々と実験してみてください。 ただし環境のサイズを大きくした場合は、学習の収束により時間がかかること[4]、行動価値関数を可視化する際は毎回モニタとして出力することなどに気を付けてください。
崖歩きは簡単な例ではありますが、エージェントシミュレーションに強化学習を組み込んだモデルを作成する上で色々と応用が効くので、今回を含め4回に分けて解説したいと思います。 次回、このモデルの S4 での作成手順について詳しく見ていきます。
- Q学習のパラメータは、$\alpha = 0.1$、$\gamma = 1$、$\varepsilon = 0.1$ と設定しました。
- 正確には"最適な行動を取り続けた場合の"即時報酬の和の期待値となっています。$\varepsilon$ による行動のバラつきは加味していないということです。この点について第7回の記事で解説する予定です。
- メニューのモデルから「パラメータを編集する」を押して、基本設定タブからシミュレーション終了時間を変更することで、全体のシミュレーション時間を変えることができます。


- S4 で始める強化学習(第1回)離散イベントシミュレーションで使ってみる
- S4 で始める強化学習(第2回)離散イベントシミュレーションで作ってみる
- S4 で始める強化学習(第3回)離散イベントシミュレーションで理解を深める
- S4 で始める強化学習(第4回)エージェントシミュレーションで使ってみる
- S4 で始める強化学習(第5回)エージェントシミュレーションで作ってみる(1/2)
- S4 で始める強化学習(第6回)エージェントシミュレーションで作ってみる(2/2)
- S4 で始める強化学習(第7回)エージェントシミュレーションで理解を深める
- S4で始める強化学習(第8回)在庫管理問題で使ってみる
- S4で始める強化学習(第9回)在庫管理問題で作ってみる(1/3)
- S4で始める強化学習(第10回)在庫管理問題で作ってみる(2/3)
- S4で始める強化学習(第11回)在庫管理問題で作ってみる(3/3)
- S4で始める強化学習(第12回)在庫管理問題で理解を深める









