- HOME
- S4 で始める強化学習(第1回)離散イベントシミュレーションで使ってみる

更新日:2026年4月30日 15:43
公開日:2022年4月 7日 18:21
本記事は当社が発行しているシミュレーションメールマガジンVol. 6の記事です。 シミュレーションメールマガジンの詳細・購読申込はこちら のサポートページから
はじめに
こんにちは、シミュレーション&マイニング部の大坪です。
本講座では強化学習と呼ばれる手法を、S4 Simulation System(以後 S4)で活用する方法について紹介していきます。 強化学習とは「エージェント」が「環境」と相互作用しながら「報酬」を最大化するような行動を学習する手法です。 環境の例としてシミュレーターがあり、したがってシミュレーションと相性の良い手法であると言えます。
本講座では、強化学習について詳しくは解説しません。 S4ユーザーの方が最初の一歩として、とにかく強化学習を使った動くものを作れるようになることを目標としています。 シミュレーションと強化学習の組み合わせでどのようなことができるか雰囲気だけでも知りたいという方も、是非お読みください。
今回は、離散イベントシミュレーションで強化学習を使うモデルを紹介し、S4 でシミュレーションする様子をお見せします。
窓口の割り当て問題
離散イベントシミュレーションで強化学習を使うミニマルなモデルとして、窓口の割り当て問題[1]を考えます。
例えば、窓口が2つある銀行があったとします。窓口の利用時間は平均のわからない指数分布に従うとし、既に利用客がいた場合は待機列に並んで、一度並んだら隣の窓口に移動できないとします。お客さんが一定の時間間隔で来店するとき[2]、どちらの窓口の待機列に案内すれば平均通過時間(待機列に並び始めてから窓口の利用を終えるまでの時間の平均)を短くできるかという問題です。
とても単純な問題ですが、同様のシチュエーションは日常生活でもよく見かけます。 余談ですが、私が1回目のコロナワクチンを集団接種で受けたときは複数のブースに行列ができており、最適化しがいがあると感じました。
- 文献として Steven J. Bradtke and Michael O. Duff, Reinforcement Learning Methods for Continuous-Time Markov Decision Problems, NIPS 1994 を参照しました。英語ではrouting to two heterogeneous serversと言うようです。
- ポアソン過程とするとより自然なモデルになりますが、その場合はセミマルコフ決定過程という定式化が必要になるので、ここでは簡単のため一定間隔としています。S4はセミマルコフ決定過程にも対応しており、実際にその場合にシミュレーションしても同様の結果が得られます。
S4 で実装
このモデルを S4 で実装した例をこちらからダウンロードできます。S4 をお持ちの方は、各.s4ファイルを S4 の画面上にドラッグ&ドロップして、プロジェクトをインポートしてみてください。
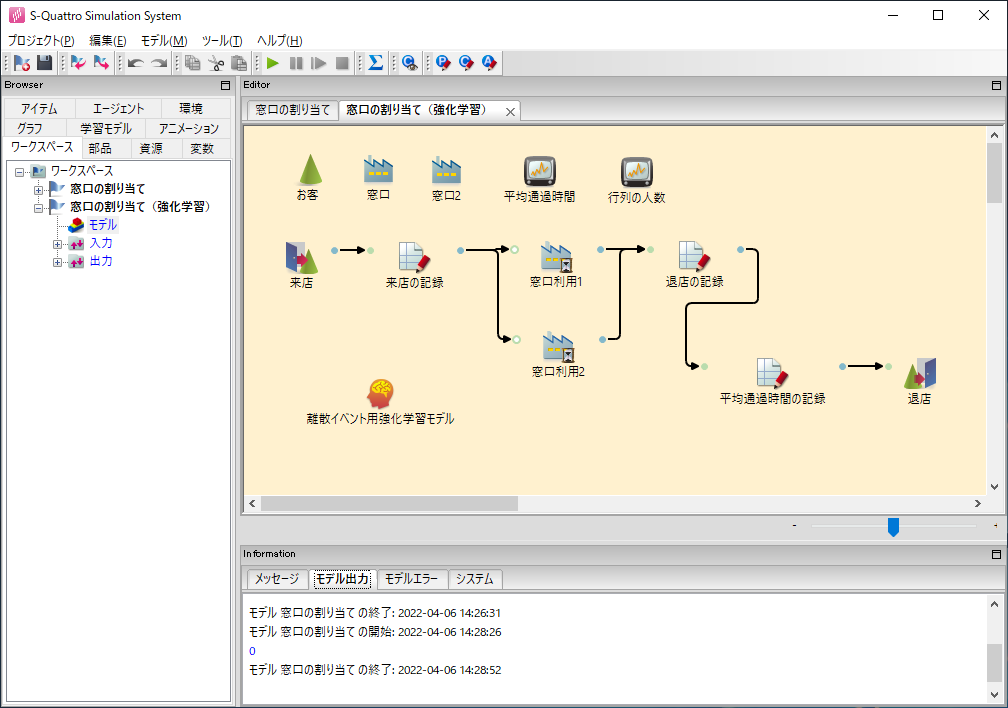
窓口の割り当てという名のプロジェクトでは、お客さんの割り当てを一様ランダムに行った場合をシミュレーションします。窓口の割り当て(強化学習)という名のプロジェクトでは、お客さんの割り当てを強化学習エージェントが行った場合をシミュレーションします。エージェントはそれぞれの窓口に何人並んでいるかを観測して、それに基づいて判断を行っていきます。エージェントも最初のうちは適当に割り当てを行いますが、実際に行列の人数がどう増減したかを学習して徐々に賢く判断できるようになります。
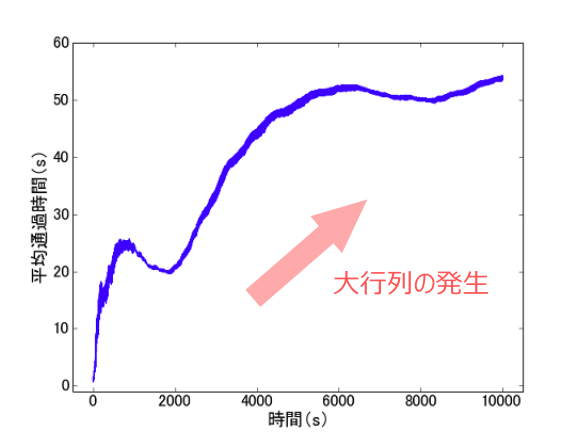
どちらのプロジェクトもお客さんは1秒ごとに来店し、窓口の利用時間はそれぞれ平均1秒および2秒の指数分布に従うと設定しています(もちろんエージェントはこれらの情報を知りません)。実際に1万秒シミュレーションしたときの平均通過時間の時間変化の様子を以下に示します。なおここでは簡単のため、平均通過時間は初期時刻からの積算で計算しています。
- ランダムに割り当てた場合
- 強化学習エージェントが割り当てを行った場合
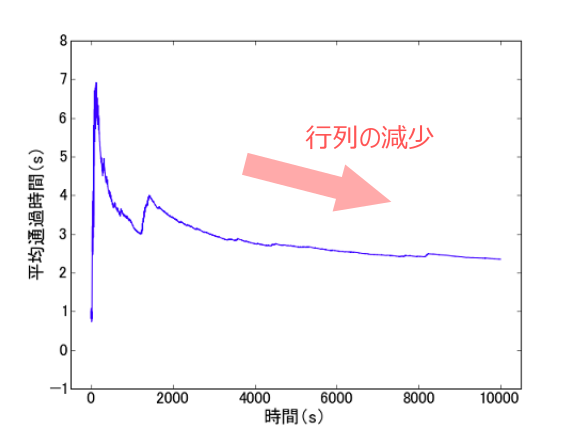
ランダムに割り当てを行うと大行列が発生して平均通過時間が長くなるのに対して、強化学習エージェントを使うと平均通過時間を短く保てていることがわかります。特に最初の数100秒では上手い割り当てができず平均通過時間が長くなっているものの、時間が経つにつれてより上手な判断ができるようになっていることが読み取れます。確率的なシミュレーションなので実行するたびに結果は変わりますが、概ね同様の結果が得られます。
ランダムに割り当てを行うと大行列が発生してしまうのは、片方の窓口が空いているのにも関わらず、行列のできている窓口に案内するというような非合理的な行動を定期的に起こすためです。 実際には、お客さんを行列の少ない方に案内し続けるという簡単なルールでそのような大行列の発生は抑えられるので、この例からは強化学習を使うありがたみはあまり感じられないかもしれません。 しかし、強化学習を使うことで、行列の長さが同じだったときにより利用時間の短い方に案内することや、利用時間が時間変化したときに合わせて行動パターンを変えるというようなことが可能になります。また、今回は窓口が2つの場合を考えましたが、3つ以上の場合に拡張することもでき、そのような複雑な問題設定では人手でルールを考えることは難しくなります。
次回以降、強化学習の設定および S4 で実装する方法や、実際にどのような行動パターンを学習したかについて詳しく見ていきたいと思います。


- S4 で始める強化学習(第1回)離散イベントシミュレーションで使ってみる
- S4 で始める強化学習(第2回)離散イベントシミュレーションで作ってみる
- S4 で始める強化学習(第3回)離散イベントシミュレーションで理解を深める
- S4 で始める強化学習(第4回)エージェントシミュレーションで使ってみる
- S4 で始める強化学習(第5回)エージェントシミュレーションで作ってみる(1/2)
- S4 で始める強化学習(第6回)エージェントシミュレーションで作ってみる(2/2)
- S4 で始める強化学習(第7回)エージェントシミュレーションで理解を深める
- S4で始める強化学習(第8回)在庫管理問題で使ってみる
- S4で始める強化学習(第9回)在庫管理問題で作ってみる(1/3)
- S4で始める強化学習(第10回)在庫管理問題で作ってみる(2/3)
- S4で始める強化学習(第11回)在庫管理問題で作ってみる(3/3)
- S4で始める強化学習(第12回)在庫管理問題で理解を深める









